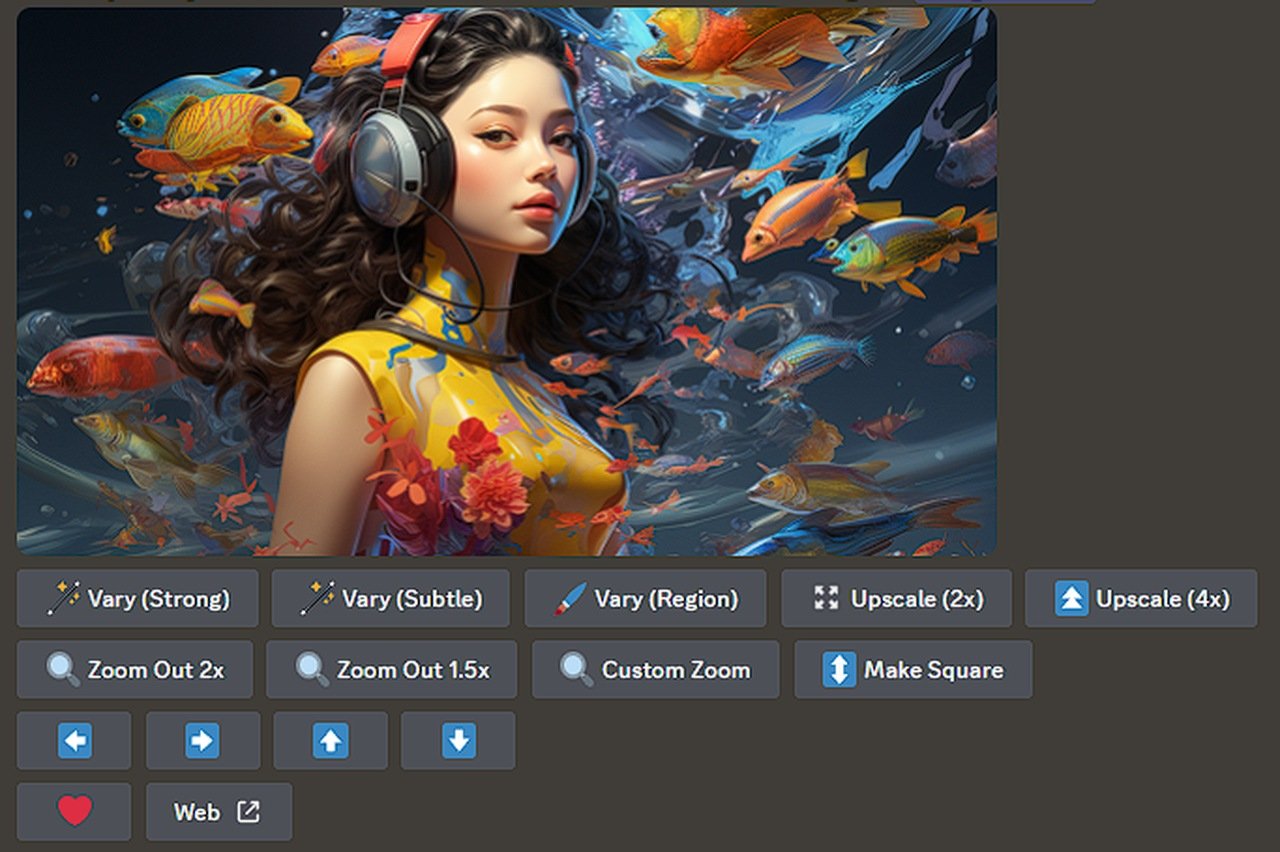
If you would like to know how to quickly and easily swap the face of one model to another in an image or advertising campaign. You will be pleased to know the world of digital imagery is taking an impressive leap forward with the advent of face swapping technology such as Fooocus. This sophisticated software is blending the lines between what’s real and what’s computer-generated, allowing users to insert AI-created faces into actual photographs with stunning accuracy.
Leading the charge in this field is the seamless integration of faces, either from a collection of AI-generated options or from your own uploaded images. To achieve the best possible outcome when using real-life photos, it’s essential to start with high-resolution and well-lit pictures. These high-quality images help to avoid common problems that can arise during the face swapping process, such as mismatched textures or visible seams.
Image face swapping made easy with Fooocus
The key to a successful face swap lies in the careful adjustment of the software’s settings. Paying close attention to the ‘stop at’ and ‘weight’ options is crucial, as they control how much of the swap is applied and how the original and new faces blend together. By experimenting with these settings, users can find the perfect balance that results in a natural-looking integration of the new face into the existing photo.

Here are some other articles you may find of interest on the subject of AI art generators :
To refine the swapped image further, the use of control nets, like canny, is indispensable. These tools help adjust the pose and the outlines of the face, ensuring that the new face fits perfectly within the context of the base photo. This attention to detail is what maintains the natural look of the image, matching the edges and contours to make the swap believable.
After the initial swap, some post-swap touch-ups might be necessary to achieve a flawless result. Adjusting the lighting, contrast, or color balance can help the new face blend in more convincingly. The goal is to create an image that not only looks authentic but also retains the essence of the original photo.
Using multiple reference images can greatly enhance the quality of the final product. By providing the software with various angles and expressions of the face, the AI can develop a more detailed understanding, which in turn improves the accuracy and realism of the swapped face.
When choosing the base photo and the face to swap, it’s important to consider the compatibility of factors such as lighting, resolution, and perspective. This careful selection is what makes the difference between a face swap that looks artificial and one that’s indistinguishable from reality.
It’s also vital to be aware of the potential biases present in AI image generation. These biases can affect how accurately the likeness is reproduced, especially when dealing with a diverse range of faces. Being conscious of and addressing these biases is crucial for ensuring that the representations are fair and accurate.
The Fooocus face swapping software is a fascinating blend of artificial intelligence and real-world imagery, offering users the ability to alter images in ways that are both creative and captivating. By following these guidelines, you can refine your settings, perfect your images, and tackle biases to produce exceptional face-swapped photos. Whether you’re looking to entertain or to enhance your professional toolkit, becoming adept at face swapping opens up a world of imaginative possibilities.
Image Credit : Monzon Media
Filed Under: Guides, Top News
Latest timeswonderful Deals
Disclosure: Some of our articles include affiliate links. If you buy something through one of these links, timeswonderful may earn an affiliate commission. Learn about our Disclosure Policy.