


If you are interested in trying out the latest AI models and large language models that have been trained in different ways. Or would simply like one of the open source AI models running locally on your home network. Assisting you with daily tasks. You will be pleased to know that it is really easy to run LLM and hence AI Agents on your local computer without the need for third-party servers. Obviously the more powerful your laptop or desktop computer have the better, but as long as you have 8GB of RAM as a minimum you should be able to run at least one or two smaller AI models such as Mistral and others.
Running AI models locally opens up opportunities for individuals and small businesses to experiment and innovate with AI without the need for expensive servers or cloud-based solutions. Whether you’re a student, an AI enthusiast, or a professional researcher, you can now easily run AI models on your PC, Mac, or Linux machine.
One of the most user-friendly tools for this purpose is LM Studio, a software that allows you to install and use a variety of AI models. With a straightforward installation process, you can have LM Studio set up on your computer in no time. It supports a wide range of operating systems, including Windows, macOS, and Linux, making it accessible to a broad spectrum of users.
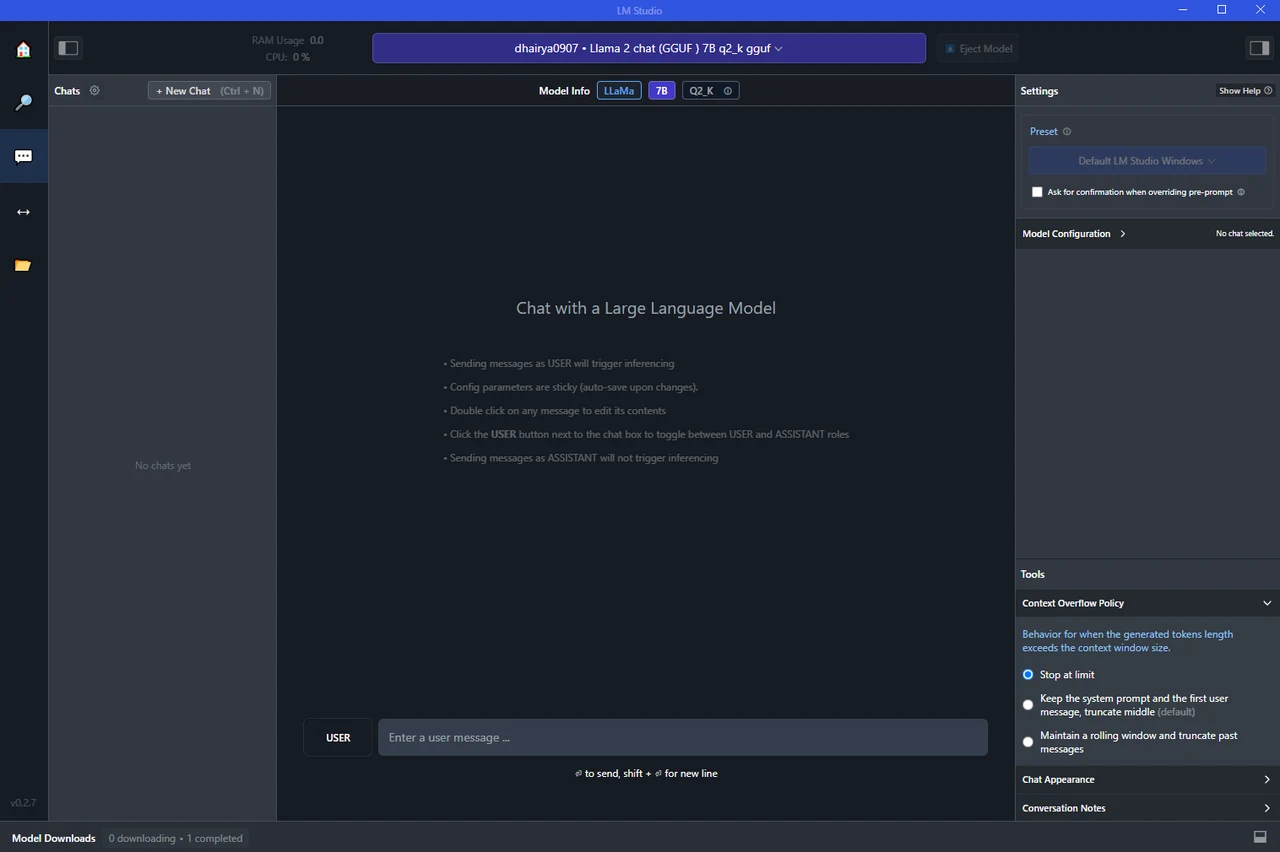
The user interface of LM Studio is designed with both beginners and advanced users in mind. The advanced features are neatly tucked away, so they don’t overwhelm new users but are easily accessible for those who need them. For instance, you can customize options and presets to tailor the software to your specific needs.
LM Studio dashboard
Other articles we have written that you may find of interest on the subject of running AI models locally
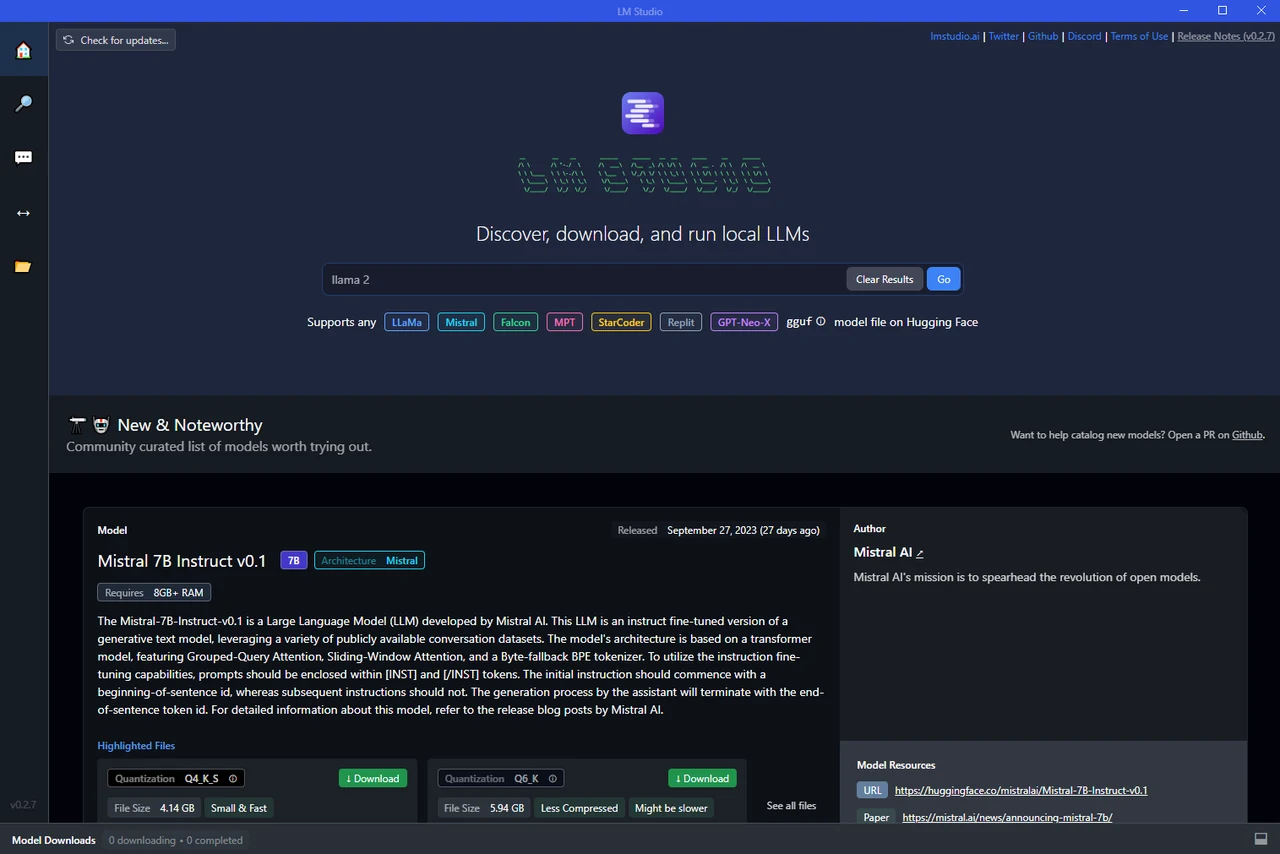
LM Studio supports several AI models, including large language models. It even allows for running quantized models in GF format, providing a more efficient way to run these models on your computer. The flexibility to download and add different models is another key feature. Whether you’re interested in NLP, image recognition, or any other AI application, you can find a model that suits your needs.
Search for AI models and LLMs
AVX2 support required
Your computer will need to support AVX2 here are a few ways to check what CPU or system is running. Once you know you can then do a quick search to see if the specifications list support for AVX2. You can also ask ChatGPT once you know your CPU. obviously CPUs after it’s OpenAI’s cut-off date are most likely to support AVX2.
Windows:
- Open the Command Prompt.
- Run the command
systeminfo. - Look for your CPU model in the displayed information, then search for that specific CPU model online to find its specifications.
macOS:
- Go to the Apple Menu -> About This Mac -> System Report.
- Under “Hardware,” find the “Total Number of Cores” and “Processor Name.”
- Search for that specific CPU model online to check its specifications.
Linux:
- Open the Terminal.
- Run the command
lscpuorcat /proc/cpuinfo. - Check for the flag
avx2in the output.
Software Utility:
You can use third-party software like CPU-Z (Windows) or iStat Menus (macOS) to see detailed specifications of your CPU, including AVX2 support.
Vendor Websites:
Visit the CPU manufacturer’s website and look up your CPU model. Detailed specifications should list supported instruction sets.
Direct Hardware Check:
If you have the skill and comfort level to do so, you can directly check the CPU’s markings and then refer to vendor specifications.
For Windows users with an M2 drive, LM Studio can be run on this high-speed storage device, providing enhanced performance. However, as mentioned before, regardless of your operating system, one crucial factor to consider is the RAM requirement. As a rule of thumb, a minimum of 8 GB of RAM is recommended to run smaller AI models such as Mistral. Larger models may require more memory, so it’s important to check the specifications of the models you’re interested in using.
In terms of model configuration and inference parameters, LM Studio offers a range of options. You can tweak these settings to optimize the performance of your models, depending on your specific use case. This level of control allows you to get the most out of your AI models, even when running them on a personal computer.
One of the most powerful features of LM Studio is the ability to create a local host and serve your model through an API. This means you can integrate your model into other applications or services, providing a way to operationalize your AI models. This feature transforms LM Studio from a mere tool for running AI models locally into a platform for building and deploying AI-powered applications.
Running AI models locally on your PC, Mac, or Linux machine is now easier than ever. With tools like LM Studio, you can experiment with different models, customize your settings, and even serve your models through an API. Whether you’re a beginner or a seasoned AI professional, these capabilities open up a world of possibilities for innovation and exploration in the field of AI.
Filed Under: Guides, Top News
Latest timeswonderful Deals
Disclosure: Some of our articles include affiliate links. If you buy something through one of these links, timeswonderful may earn an affiliate commission. Learn about our Disclosure Policy.









