Recently posted benchmarks have revealed how capable the brand-new Apple M4 chip is in terms of single-core performance, outpacing even the best processors on the market.
As spotted by Tom’s Hardware, there’s a new champion in the Geekbench 6 CPU benchmarks as the iPad Pro line featuring the M4 chip actually beat out the previously leading Intel Core i9-14900KS in single-core benchmarks. Apple’s latest silicon scored confident averages of around 3,800 in comparison to Team Blue’s average of 3,100.
While things aren’t quite as exciting in terms of multi-core performance, this marks an incredibly rare occassion where mobile hardware can not only stand in league with desktop, but surpass it. It’s due in part to the new 10-core (4P + 6E) processor of the M4 chip which is bolstered by 10-core GPU, and a larger 16-core Neural Engine weighing in at 38 TOPS.
Apple claims that the M4 chip is roughly 50% faster than the M2 processor that you’ll find in the incoming Apple iPad Air models as well as older MacBooks and iMacs from 2022. The M4 silicon’s specs confidently tout improved branch prediction, next-gen ML accelerators, and a deeper execution engine according to Apple.
It’s still early days for the new iPad Pro lineup which also feature what the company describes as a “Tandem OLED” display, and appear to be pushing the form factor in new directions. That means we can’t quite draw a definitive line on Apple’s tablets beating out leading desktop models across the board, even if the early reports are encouraging.
These strong figures are due in part to the newly revised Neural Engine which is the largest on Apple Silicon yet. Considering many manufacturers such as AMD and Intel are going all-in on AI computing with their incoming CPU generations, it’s good to see Apple make a statement here, as the fourth-generation in-house chip makes a strong impression.
The start of what’s to come from the AI revolution
It’s still early days for AI computing regardless of form factor and time will tell exactly how well-optimized iPad OS software is to the new M4 chipset and more advanced Neural Engine. AMD has thrown its hat into the ring with the upcoming AMD Ryzen AI 9 HX 170 flagship with an NPU of up to 77 TOPS according to a recent Asus leak.
Get the hottest deals available in your inbox plus news, reviews, opinion, analysis and more from the TechRadar team.
Meanwhile, Intel already has a piece on the board with the Core Ultra 100 chips as Meteor Lake debuted in laptops last year. The real test for what the M4 chip is able to do will emerge when the playing ground is levelled. We’re expecting Intel Arrow Lake later this year, so Team Red and Team Blue could widen the gap again. Until then, however, Apple’s proven its tablets can hold their own against x86 confidently.
Benchmarks giving an early look at the performance of the Apple M4 processor in the 2024 iPad Pro reveal that the new chip is 21% faster than its predecessor.
The processor launched in the latest iPad but is expected to make its way to Mac later this year.
M4 continues long string of Apple performance improvements
The M4 is built on second-generation three-nanometer technology. It has up to four performance cores and includes six efficiency cores — two more than M3. It’s intended to be even more power efficient than its predecessor.
When Apple unveiled the chip on Tuesday, it didn’t compare it to the M3. Instead, it said, “M4 delivers up to 1.5x faster CPU performance over the powerful M2 in the previous iPad Pro.”
Those wondering how much the processor improves over the M3 that debuted in MacBooks just seven months ago now have a (preliminary) answer. Geekbench 6 scores found on the Primate Lab website (via X) show that the M4 earned a 14,677 on the Multi-Core test. For comparison, the M3 MacBook Pro scored 12,102 on that same test, according to Engadet, so the new one did 21% better. (Incidentally, M3 was 25% better than M2.)
The M4’s Single-Core score was 3,767. The M3 MBA scored 3,190, so the newer processor came in 18% better.
Note that these scores are preliminary. After its big announcement on Tuesday, the 2024 iPad Pro is just now reaching reviewers so the publication of their reviews won’t be for several more days. It’s possible final benchmark scores from reviewers will be even higher than these early ones. The tablet won’t get to customers until May 15.
Other specs revealed by Geekbench 6 show that each CPU core runs at 4.4 GHz. The chip has 16GB of RAM, which means the iPad Pro it’s installed in has at least 1TB of storage.
Apple M4: An emphasis on AI
Part of the upgrades in the new processor are intended to make it better at running artificial intelligence software.
At its announcement, Apple said, “M4 has Apple’s fastest Neural Engine ever, capable of up to 38 trillion operations per second, which is faster than the neural processing unit of any AI PC today. Combined with faster memory bandwidth, along with next-generation machine learning (ML) accelerators in the CPU, and a high-performance GPU, M4 makes the new iPad Pro an outrageously powerful device for artificial intelligence.”
We don’t yet have benchmark scores to indicate definitively how well the processor will run AI software. But Apple is expected to unveil iPadOS 18 at WWDC24 in June, and Apple CEO Tim Cook himself strongly hinted that new features in all the company’s operating systems will heavily focus on AI.
The end of 2024 and the beginning of 2025 will bring “new iMacs, a low-end 14-inch MacBook Pro, high-end 14-inch and 16-inch MacBook Pros, and Mac minis — all with M4 chips,” reported Bloomberg in April.
Of course, these won’t all use the basic version of the processor that’s in the iPad Pro. Expect to see M4 Pro, M4 Max, etc. in the coming months.
Highlights of the Apple M4 processor. (Click/tap for larger image) Image: Apple
Artificial intelligence (AI) systems, such as the chatbot ChatGPT, have become so advanced that they now very nearly match or exceed human performance in tasks including reading comprehension, image classification and competition-level mathematics, according to a new report (see ‘Speedy advances’). Rapid progress in the development of these systems also means that many common benchmarks and tests for assessing them are quickly becoming obsolete.
These are just a few of the top-line findings from the Artificial Intelligence Index Report 2024, which was published on 15 April by the Institute for Human-Centered Artificial Intelligence at Stanford University in California. The report charts the meteoric progress in machine-learning systems over the past decade.
In particular, the report says, new ways of assessing AI — for example, evaluating their performance on complex tasks, such as abstraction and reasoning — are more and more necessary. “A decade ago, benchmarks would serve the community for 5–10 years” whereas now they often become irrelevant in just a few years, says Nestor Maslej, a social scientist at Stanford and editor-in-chief of the AI Index. “The pace of gain has been startlingly rapid.”
Stanford’s annual AI Index, first published in 2017, is compiled by a group of academic and industry specialists to assess the field’s technical capabilities, costs, ethics and more — with an eye towards informing researchers, policymakers and the public. This year’s report, which is more than 400 pages long and was copy-edited and tightened with the aid of AI tools, notes that AI-related regulation in the United States is sharply rising. But the lack of standardized assessments for responsible use of AI makes it difficult to compare systems in terms of the risks that they pose.
The rising use of AI in science is also highlighted in this year’s edition: for the first time, it dedicates an entire chapter to science applications, highlighting projects including Graph Networks for Materials Exploration (GNoME), a project from Google DeepMind that aims to help chemists discover materials, and GraphCast, another DeepMind tool, which does rapid weather forecasting.
Growing up
The current AI boom — built on neural networks and machine-learning algorithms — dates back to the early 2010s. The field has since rapidly expanded. For example, the number of AI coding projects on GitHub, a common platform for sharing code, increased from about 800 in 2011 to 1.8 million last year. And journal publications about AI roughly tripled over this period, the report says.
ChatGPT broke the Turing test — the race is on for new ways to assess AI
Much of the cutting-edge work on AI is being done in industry: that sector produced 51 notable machine-learning systems last year, whereas academic researchers contributed 15. “Academic work is shifting to analysing the models coming out of companies — doing a deeper dive into their weaknesses,” says Raymond Mooney, director of the AI Lab at the University of Texas at Austin, who wasn’t involved in the report.
That includes developing tougher tests to assess the visual, mathematical and even moral-reasoning capabilities of large language models (LLMs), which power chatbots. One of the latest tests is the Graduate-Level Google-Proof Q&A Benchmark (GPQA)1, developed last year by a team including machine-learning researcher David Rein at New York University.
The GPQA, consisting of more than 400 multiple-choice questions, is tough: PhD-level scholars could correctly answer questions in their field 65% of the time. The same scholars, when attempting to answer questions outside their field, scored only 34%, despite having access to the Internet during the test (randomly selecting answers would yield a score of 25%). As of last year, AI systems scored about 30–40%. This year, Rein says, Claude 3 — the latest chatbot released by AI company Anthropic, based in San Francisco, California — scored about 60%. “The rate of progress is pretty shocking to a lot of people, me included,” Rein adds. “It’s quite difficult to make a benchmark that survives for more than a few years.”
Cost of business
As performance is skyrocketing, so are costs. GPT-4 — the LLM that powers ChatGPT and that was released in March 2023 by San Francisco-based firm OpenAI — reportedly cost US$78 million to train. Google’s chatbot Gemini Ultra, launched in December, cost $191 million. Many people are concerned about the energy use of these systems, as well as the amount of water needed to cool the data centres that help to run them2. “These systems are impressive, but they’re also very inefficient,” Maslej says.
Costs and energy use for AI models are high in large part because one of the main ways to make current systems better is to make them bigger. This means training them on ever-larger stocks of text and images. The AI Index notes that some researchers now worry about running out of training data. Last year, according to the report, the non-profit research institute Epoch projected that we might exhaust supplies of high-quality language data as soon as this year. (However, the institute’s most recent analysis suggests that 2028 is a better estimate.)
AI ‘breakthrough’: neural net has human-like ability to generalize language
Ethical concerns about how AI is built and used are also mounting. “People are way more nervous about AI than ever before, both in the United States and across the globe,” says Maslej, who sees signs of a growing international divide. “There are now some countries very excited about AI, and others that are very pessimistic.”
In the United States, the report notes a steep rise in regulatory interest. In 2016, there was just one US regulation that mentioned AI; last year, there were 25. “After 2022, there’s a massive spike in the number of AI-related bills that have been proposed” by policymakers, Maslej says.
Regulatory action is increasingly focused on promoting responsible AI use. Although benchmarks are emerging that can score metrics such as an AI tool’s truthfulness, bias and even likability, not everyone is using the same models, Maslej says, which makes cross-comparisons hard. “This is a really important topic,” he says. “We need to bring the community together on this.”
Comino, known for its liquid-cooled servers, has finally released its new flagship for testing.
The Comino Grando Server has been designed to meet a broad spectrum of high-performance computing needs, ranging from data analytics to gaming.
In a comprehensive test by StorageReview, the Grando Server, alongside a Grando Workstation variation, was put through a series of rigorous benchmarks including Blender 4.0, Luxmark, OctaneBench, Blackmagic RAW Speed Test, 7-zip Compression, and Y-Cruncher.
(Image credit: Comino)
The server, equipped with six Nvidia RTX 4090s, AMD‘s Threadripper PRO 5995WX CPU, 512GB DDR5 DRAM, a 2TB NVMe SSD, and four 1600W PSUs, delivered impressive results, as you’d expect from those specifications.
Grando Server features advanced liquid cooling, allowing it to accommodate those six Nvidia 4090 GPUs side by side, a setup that Lyle Smith from StorageReview noted would be impossible with air cooling.
GPU-driven performance systems done right
The main difference between the Grando Server and Grando Workstation lies in their GPU and CPU capabilities. With its higher core count, the Server model is well-suited for parallel processing tasks. While still powerful, the Workstation offers fewer cores and is better suited for balanced performance across various applications.
The Grando Workstation that Smith tested featured four Nvidia A100 professional GPUs, a Threadripper Pro 3975WX processor, 512GB DDR5 DRAM, and a 2TB NVMe SSD.
In his review, Smith found the Comino Grando Server and Workstation to be “prime examples of GPU-driven performance systems done right.”
He said, “Performance-wise, the benchmark results paint a clear picture: the Grando Server excels in GPU-intensive tests like OctaneBench and Blender 4.0, highlighting its capability to breeze through high-end rendering jobs. With its tailored CPU-GPU balance, the Workstation version offers versatility for various professional applications. The speed and efficiency of both systems in managing large datasets, as evidenced by the 7-zip Compression and Y-Cruncher benchmarks, underscore their capacity for handling data-intensive operations, a critical advantage in today’s data-driven landscape.”
StorageReview approved of the Comino Grando systems so much that it rated them one of its “Best of 2024” award winners.
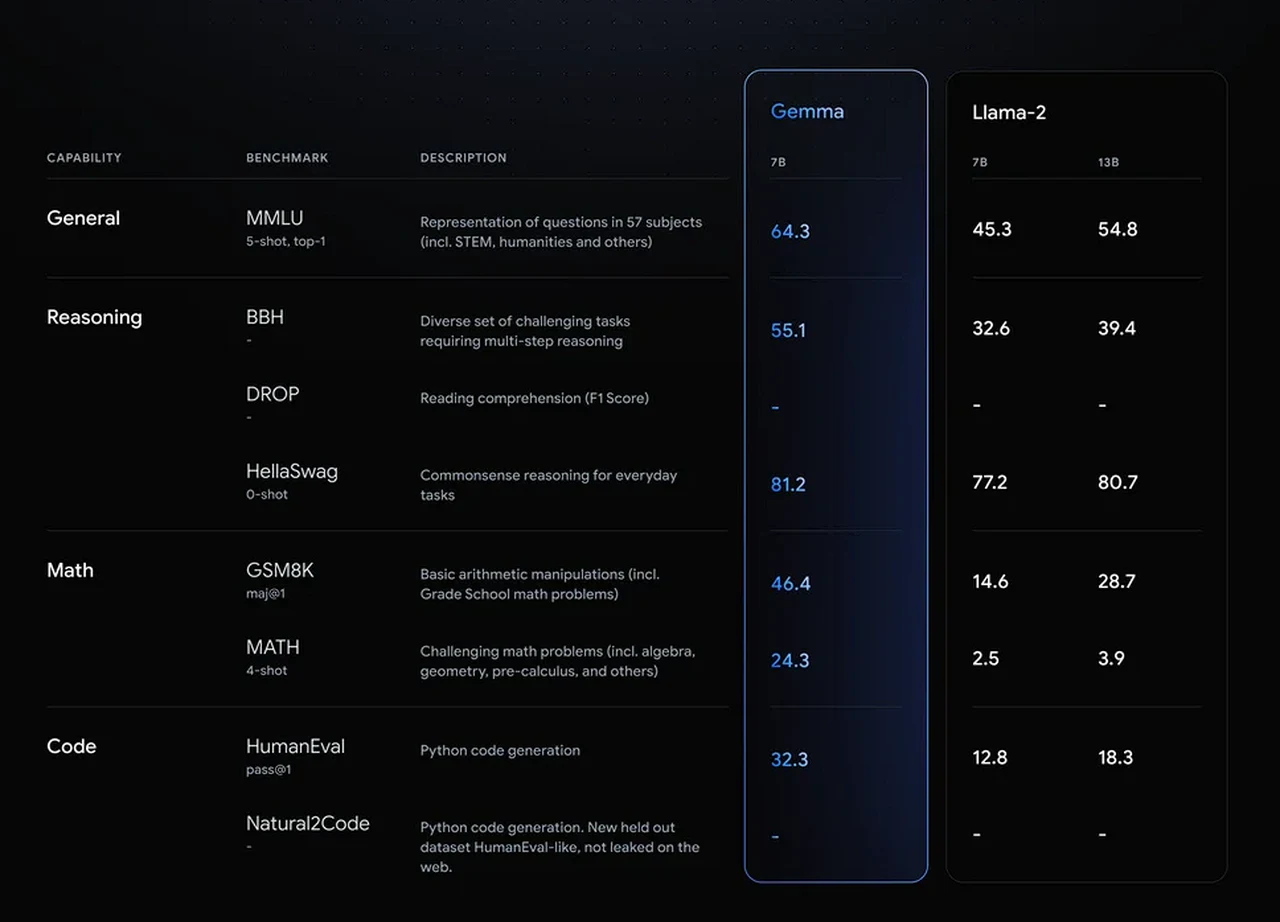
Google has unveiled Gemma, a groundbreaking collection of open-source language models that are reshaping how we interact with machines through language. Gemma is a clear indication of Google’s dedication to contributing to the open-source community and aim to improve how we use machine learning technologies check out the benchmarks comparing Gemma AI vs Llama-2 the table below for performance comparison.
At the heart of Gemma is the Gemini technology, which ensures these models are not just efficient but also at the forefront of language processing. The Gemma AI models are designed to work on a text-to-text basis and are decoder-only, which means they are particularly good at understanding and generating text that sounds like it was written by a human. Although they were initially released in English, Google is working on adding support for more languages, which will make them useful for even more people.
Gemma AI features and usage
Google has released two versions: Gemma 2B and Gemma 7B. Each size is released with pre-trained and instruction-tuned variants.
As well as a new Responsible Generative AI Toolkit provides guidance and essential tools for creating safer AI applications with Gemma.
Google also providing toolchains for inference and supervised fine-tuning (SFT) across all major frameworks: JAX, PyTorch, and TensorFlow through native Keras 3.0.
Access Gemma via ready-to-use Colab and Kaggle notebooks, alongside integration with popular tools such as Hugging Face, MaxText, NVIDIA NeMo and TensorRT-LLM, make it easy to get started with Gemma.
Pre-trained and instruction-tuned Gemma models can run on your laptop, workstation, or Google Cloud with easy deployment on Vertex AI and Google Kubernetes Engine (GKE).
Optimization across multiple AI hardware platforms ensures industry-leading performance, including NVIDIA GPUs and Google Cloud TPUs.
Terms of use permit responsible commercial usage and distribution for all organizations, regardless of size.
Google Gemma vs Llama 2
The Gemma suite consists of four models. Two of these are particularly powerful, with 7 billion parameters, while the other two are still quite robust with 2 billion parameters. The number of parameters is a way of measuring how complex the models are and how well they can understand the nuances of language.
Open source AI models from Google
Gemma is built for the open community of developers and researchers powering AI innovation. You can start working with Gemma today using free access in Kaggle, a free tier for Colab notebooks, and $300 in credits for first-time Google Cloud users. Researchers can also apply for Google Cloud credits of up to $500,000 to accelerate their projects.
Here are some other articles you may find of interest on the subject of Google Gemini
Training the AI models
To train models as sophisticated as Gemma, Google has used a massive dataset. This dataset includes 6 trillion tokens, which are pieces of text from various sources. Google has been careful to leave out any sensitive information to make sure they meet privacy and ethical standards.
For the training of the Gemma models, Google has used the latest technology, including the TPU V5e, which is a cutting-edge Tensor Processing Unit. The development of the models has also been supported by the JAX and ML Pathways frameworks, which provide a strong foundation for their creation.
The initial performance benchmarks for Gemma look promising, but Google knows there’s always room for improvement. That’s why they’re inviting the community to help refine the models. This collaborative approach means that anyone can contribute to making Gemma even better.
Google has put in place a terms of use policy for Gemma to ensure it’s used responsibly. This includes certain restrictions, like not using the models for chatbot applications. To get access to the model weights, you have to fill out a request form, which allows Google to keep an eye on how these powerful tools are being used.
For those who develop software or conduct research, the Gemma models work well with popular machine learning libraries, such as Keras NLP. If you use PyTorch, you’ll find versions of the models that have been optimized for different types of computers.
The tokenizer that comes with Gemma can handle a large number of different words and phrases, with a vocabulary size of 256,000. This shows that the models can understand and create a wide range of language patterns, and it also means that they’re ready to be expanded to include more languages in the future.
Google’s Gemma models represent a significant advancement in the field of open-source language modeling. With their sophisticated design, thorough training, and the potential for improvements driven by the community, these models are set to become an essential tool for developers and researchers. As you explore what Gemma can do, your own contributions to its development could have a big impact on the future of how we interact with machines using natural language.
Filed Under: Technology News, Top News
Latest timeswonderful Deals
Disclosure: Some of our articles include affiliate links. If you buy something through one of these links, timeswonderful may earn an affiliate commission. Learn about our Disclosure Policy.
Mistral AI has recently unveiled an innovative mixture of experts model that is making waves in the field of artificial intelligence. This new model, which is now available through Perplexity AI at no cost, has been fine-tuned with the help of the open-source community, positioning it as a strong contender against the likes of the well-established GPT-3.5. The model’s standout feature is its ability to deliver high performance while potentially requiring as little as 4 GB of VRAM, thanks to advanced compression techniques that preserve its effectiveness. This breakthrough suggests that even those with limited hardware resources could soon have access to state-of-the-art AI capabilities. Mistral AI explain more about the new Mixtral 8x7B :
“Today, the team is proud to release Mixtral 8x7B, a high-quality sparse mixture of experts model (SMoE) with open weights. Licensed under Apache 2.0. Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference. It is the strongest open-weight model with a permissive license and the best model overall regarding cost/performance trade-offs. In particular, it matches or outperforms GPT3.5 on most standard benchmarks.”
The release of Mixtral 8x7B by Mistral AI marks a significant advancement in the field of artificial intelligence, specifically in the development of sparse mixture of experts models (SMoEs). This model, Mixtral 8x7B, is a high-quality SMoE with open weights, licensed under Apache 2.0. It is notable for its performance, outperforming Llama 2 70B on most benchmarks while offering 6x faster inference. This makes Mixtral the leading open-weight model with a permissive license, and it is highly efficient in terms of cost and performance trade-offs, even matching or surpassing GPT3.5 on standard benchmarks.
Mixtral 8x7B exhibits several impressive capabilities. It can handle a context of 32k tokens and supports multiple languages, including English, French, Italian, German, and Spanish. Its performance in code generation is strong, and it can be fine-tuned into an instruction-following model, achieving a score of 8.3 on MT-Bench.
Mistral AI mixture of experts model MoE
The benchmark achievements of Mistral AI’s model are not just impressive statistics; they represent a significant stride forward that could surpass the performance of existing models such as GPT-3.5. The potential impact of having such a powerful tool freely available is immense, and it’s an exciting prospect for those interested in leveraging AI for various applications. The model’s performance on challenging datasets, like H SWAG and MML, is particularly noteworthy. These benchmarks are essential for gauging the model’s strengths and identifying areas for further enhancement.
Here are some other articles you may find of interest on the subject of Mistral AI :
The architecture of Mixtral is particularly noteworthy. It’s a decoder-only sparse mixture-of-experts network, using a feedforward block that selects from 8 distinct groups of parameters. A router network at each layer chooses two groups to process each token, combining their outputs additively. Although Mixtral has 46.7B total parameters, it only uses 12.9B parameters per token, maintaining the speed and cost efficiency of a smaller model. This model is pre-trained on data from the open web, training both experts and routers simultaneously.
In comparison to other models like the Llama 2 family and GPT3.5, Mixtral matches or outperforms these models in most benchmarks. Additionally, it exhibits more truthfulness and less bias, as evidenced by its performance on TruthfulQA and BBQ benchmarks, where it shows a higher percentage of truthful responses and presents less bias compared to Llama 2.
Moreover, Mistral AI also released Mixtral 8x7B Instruct alongside the original model. This version has been optimized through supervised fine-tuning and direct preference optimization (DPO) for precise instruction following, reaching a score of 8.30 on MT-Bench. This makes it one of the best open-source models, comparable to GPT3.5 in performance. The model can be prompted to exclude certain outputs for applications requiring high moderation levels, demonstrating its flexibility and adaptability.
To support the deployment and usage of Mixtral, changes have been submitted to the vLLM project, incorporating Megablocks CUDA kernels for efficient inference. Furthermore, Skypilot enables the deployment of vLLM endpoints in cloud instances, enhancing the accessibility and usability of Mixtral in various applications
AI fine tuning and training
The training and fine-tuning process of the model, which includes instruct datasets, plays a critical role in its success. These datasets are designed to improve the model’s ability to understand and follow instructions, making it more user-friendly and efficient. The ongoing contributions from the open-source community are vital to the model’s continued advancement. Their commitment to the project ensures that the model remains up-to-date and continues to improve, embodying the spirit of collective progress and the sharing of knowledge.
As anticipation builds for more refined versions and updates from Mistral AI, the mixture of experts model has already established itself as a significant development. With continued support and development, it has the potential to redefine the benchmarks for AI performance.
Mistral AI’s mixture of experts model is a notable step forward in the AI landscape. With its strong benchmark scores, availability at no cost through Perplexity AI, and the support of a dedicated open-source community, the model is well-positioned to make a lasting impact. The possibility of it operating on just 4 GB of VRAM opens up exciting opportunities for broader access to advanced AI technologies. The release of Mixtral 8x7B represents a significant step forward in AI, particularly in developing efficient and powerful SMoEs. Its performance, versatility, and advancements in handling bias and truthfulness make it a notable addition to the AI technology landscape.
Image Credit: Mistral AI
Filed Under: Technology News, Top News
Latest timeswonderful Deals
Disclosure: Some of our articles include affiliate links. If you buy something through one of these links, timeswonderful may earn an affiliate commission. Learn about our Disclosure Policy.
The Raspberry Pi, an innovative and cost-effective computing device, has seen a significant evolution in its performance over the years. Even though the Raspberry Pi 5 is only available to preorder and is expected to start shipping this month first Raspberry Pi 5 benchmarks have already been servicing thanks to those who’ve been lucky enough to get their hands-on the mini PC ahead of its official retail availability.
The benchmarks have been recorded by Alasdair Allan from the official Raspberry Pi team using the Geekbench 6.2. A cross-platform processor benchmark, provides scores for single-core and multi-core performance. Single-core scores measure the processing power of one CPU core, which is crucial for applications that rely mostly on a single core to process instructions. Multi-core scores, on the other hand, measure the performance when jobs are distributed across all cores of the CPU. This is relevant for heavily threaded applications such as web browsers. Together with marks provided by Core Electronics.
Raspberry Pi 5 vs Raspberry Pi 4 benchmarks
Single core performance
In terms of single-core performance, the Raspberry Pi 5 demonstrates a significant improvement over its predecessor. It showed a 2.4 times speed increase over the Raspberry Pi 4 in single-core scores, with an average score of 764 for a 4KB page size and 774 for a 16KB page size. This improvement indicates that the Raspberry Pi 5 can handle single-core applications more efficiently, leading to smoother operation and faster execution times.
Multiple core performance
The multi-core performance of the Raspberry Pi 5 also shows a marked improvement. The device showed a 2.2 times speed increase over the Raspberry Pi 4 in multi-core scores, with an average score of 1,604 for a 4KB page size and 1,588 for a 16KB page size. This suggests that the Raspberry Pi 5 can manage heavily threaded applications more effectively, offering users an enhanced browsing experience, among other benefits.
Other articles we have written that you may find of interest on the subject of the latest Raspberry Pi mini PC :
The Raspberry Pi 5, equipped with a quad-core Arm Cortex-A76 processor clocked at 2.4GHz, offers between two and three times the CPU and GPU performance of the Raspberry Pi 4. Additionally, it provides approximately twice the memory and I/O bandwidth, enhancing the overall user experience. It’s noteworthy that the Raspberry Pi 5 is the first time Raspberry Pi silicon has been used on a flagship device, marking a significant milestone in the evolution of Raspberry Pi performance.
Overclocking performance
Overclocking, which involves increasing the clock rate of a computer’s CPU or GPU beyond the factory setting, can often improve performance. When the Raspberry Pi 5’s CPU was overclocked from 2.4GHz to 3.0GHz, it resulted in a 1.2 times increase in single-core scores. However, no similar increase was observed in multi-core scores. This indicates that while overclocking can provide a performance boost in certain situations, it might not always result in a proportional improvement in all areas of performance.
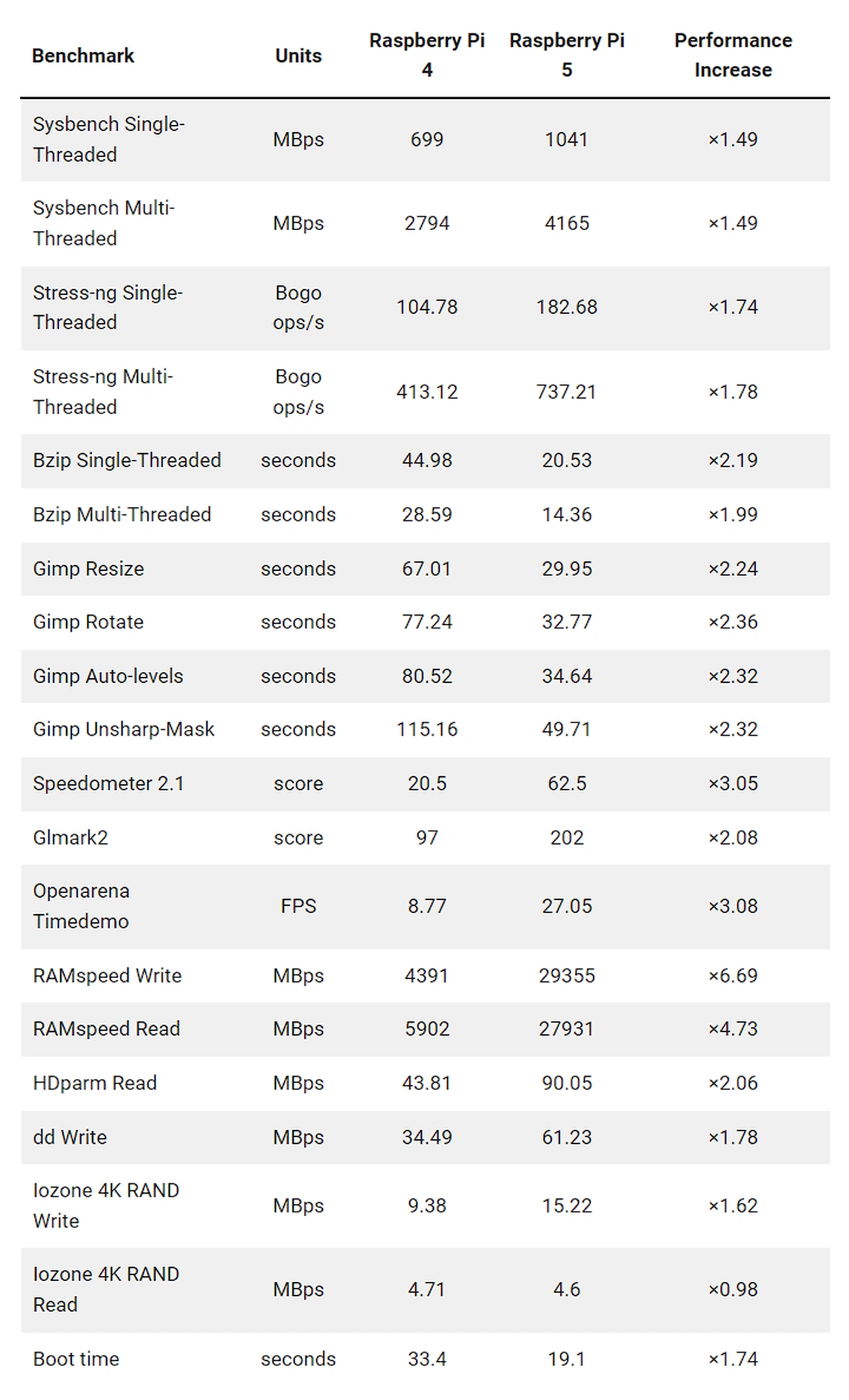
Starting with the Sysbench benchmarks, which are commonly used to test CPU performance, we observe a notable increase in performance for the Raspberry Pi 5. In single-threaded performance, the Raspberry Pi 5 achieved 1041 MBps compared to the Raspberry Pi 4’s 699 MBps, a 1.49-fold improvement. Similarly, in the multi-threaded tests, the Raspberry Pi 5 recorded 4165 MBps, again a 1.49 times enhancement over the 2794 MBps of the Raspberry Pi 4.
Turning our attention to the Stress-ng benchmarks, which stress various subsystems of a computer, the Raspberry Pi 5 displayed superior performance in both single and multi-threaded scenarios. Specifically, in single-threaded tests, the Raspberry Pi 5 managed 182.68 Bogo ops/s, an improvement of 1.74 times over the Raspberry Pi 4’s 104.78 Bogo ops/s. For the multi-threaded counterpart, the Raspberry Pi 5 achieved 737.21 Bogo ops/s, surpassing the Raspberry Pi 4’s 413.12 Bogo ops/s by 1.78 times.
Bzip, a data compression tool, showcased significant gains in performance on the Raspberry Pi 5. For single-threaded compression, the task was completed in 20.53 seconds compared to the Raspberry Pi 4’s 44.98 seconds, showing a 2.19 times performance boost. Meanwhile, in multi-threaded tasks, the Raspberry Pi 5 finished in 14.36 seconds, nearly twice as fast as the Raspberry Pi 4’s 28.59 seconds.
Discussing graphic editing capabilities, using GIMP as a benchmark, the Raspberry Pi 5 outperformed its predecessor in various tasks. Resizing an image took the Raspberry Pi 5 only 29.95 seconds, a 2.24 times improvement over the Raspberry Pi 4’s 67.01 seconds. Image rotation on the Raspberry Pi 5 was completed in 32.77 seconds, which is 2.36 times faster than the Raspberry Pi 4’s 77.24 seconds. Auto-leveling and unsharp mask adjustments also saw similar gains, with the Raspberry Pi 5 being roughly 2.32 times faster in both categories.
Regarding browser benchmarks, Speedometer 2.1 scored the Raspberry Pi 5 at 62.5, marking a threefold increase over the Raspberry Pi 4’s score of 20.5. For GPU performance, using the GImark2 benchmark, the Raspberry Pi 5 scored 202, which is a significant 2.08 times improvement over the Raspberry Pi 4’s score of 97.
The Openarena Timedemo, a measure of gaming capability, recorded the Raspberry Pi 5 at 27.05 FPS, showing a considerable 3.08 times leap over the Raspberry Pi 4’s 8.77 FPS. For memory performance, RAMspeed benchmarks indicated drastic improvements for the Raspberry Pi 5. Write speeds soared to 29355 MBps, a 6.69 times jump from the Raspberry Pi 4’s 4391 MBps. Read speeds for the Raspberry Pi 5 reached 27931 MBps, 4.73 times faster than the Raspberry Pi 4’s 5902 MBps.
In disk performance, using HDparm for reading, the Raspberry Pi 5 achieved 90.05 MBps, a 2.06 times improvement over the Raspberry Pi 4’s 43.81 MBps. The dd Write benchmark, which tests the speed of writing data to a file, showed the Raspberry Pi 5 at 61.23 MBps, a 1.78 times improvement over the Raspberry Pi 4’s 34.49 MBps. However, in the Iozone 4K RAND benchmarks, which measure random read and write speeds, the Raspberry Pi 5’s read performance was slightly lesser than its predecessor, but it did manage a 1.62 times improvement in write speeds.
Lastly, an essential metric for many users, the boot time, saw the Raspberry Pi 5 starting up in just 19.1 seconds, which is a substantial 1.74 times faster than the Raspberry Pi 4’s 33.4 seconds. The Raspberry Pi 5 demonstrates significant advancements in performance across almost all benchmarks compared to the Raspberry Pi 4. Whether it’s computing, graphics, memory, or disk operations, users can expect a more robust and efficient experience with the Raspberry Pi 5.
The Raspberry Pi 5 represents a significant leap forward in terms of performance compared to the Raspberry Pi 4. Its enhanced single-core and multi-core performance, coupled with the potential performance boost from overclocking, make it a powerful tool for a wide range of applications. As the Raspberry Pi continues to evolve, users can look forward to even more powerful, versatile, and cost-effective computing solutions in the future.
Image Credit : Core Electronics
Filed Under: Hardware, Top News
Latest timeswonderful Deals
Disclosure: Some of our articles include affiliate links. If you buy something through one of these links, timeswonderful may earn an affiliate commission. Learn about our Disclosure Policy.