por mucho tiempo, verdadero llamador Está equipado periféricamente para iPhone Por el estricto jardín amurallado de Apple, pero ya no. La compañía anunció el miércoles que implementará soporte de interfaz de programación de aplicaciones (API) para iPhones que permitirá funciones como identificación de llamadas en tiempo real y bloqueo automático de llamadas telefónicas no deseadas en dispositivos Apple. Se dice que la medida equiparará la versión iOS de la aplicación con su contraparte de Android, que ha ofrecido las funciones anteriores y más durante años.
Nuevas funciones de Truecaller para iPhone
Truecaller dice que la última actualización de su aplicación para iPhone garantiza que el dispositivo pueda aprovechar sus capacidades inteligencia artificial (AI) Capacidades de identificación de llamadas. Brinda apoyo a Manzana Marco de búsqueda de identificador de llamadas en vivo, que pretende proporcionar un identificador de llamadas en vivo. Presentado el año pasado con iOS 18Esta API permite que las aplicaciones de terceros verifiquen las llamadas entrantes en el servidor en busca de números de spam conocidos.
La API utiliza cifrado simétrico que, según la empresa, protege la privacidad del usuario. Oculta la dirección IP del cliente, utiliza autenticación anónima y oculta el número de teléfono entrante. Con su llegada, el iPhone ahora también puede beneficiarse de la capacidad de bloquear automáticamente llamadas no deseadas.
El bloqueo automático de llamadas no deseadas está disponible a nivel mundial durante el lanzamiento de la función Live Caller ID. Está disponible para los suscriptores de Truecaller Premium que utilizan un iPhone con iOS 18.2. Los usuarios gratuitos seguirán estando limitados a las funciones existentes de identificación de llamadas y búsqueda manual de números con publicidad de empresas verificadas. Gadgets 360 puede confirmar que las funciones ya están disponibles en el iPhone.
Nuevas funciones en la aplicación Truecaller para iOS
Aquí se explica cómo habilitarlo:
Actualice la aplicación Truecaller a la versión 14.0 o posterior a través de la App Store de iPhone.
se abre Configuración de iPhone > Aplicaciones > Teléfono > Identificación y bloqueo de llamadas.
Habilite todos los conmutadores de Truecaller y reinicie la aplicación.
Aunque estas características son nuevas, la compañía ha estado provocando la llegada del soporte nativo de iOS durante los últimos meses. Después de presentar la actualización de iOS 18 y la API Live Caller ID en septiembre, Alain Mamedi, cofundador de Truecaller, dijo… abonado Sus pensamientos positivos sobre X (anteriormente Twitter), afirmando que “Truecaller finalmente funciona en iPhone”.
Otra adición notable es la posibilidad de suscribirse al plan Premium Family dentro de la aplicación. La compañía dice que los usuarios ahora pueden disfrutar de funciones como Truecaller AI Assistant y compartirlas con hasta cuatro personas adicionales por un bajo precio mensual o anual. Para los usuarios de la India, la suscripción Truecaller Premium también incluye un seguro contra fraude.
Leica ha presentado su última cámara sin espejo de fotograma completo, la SL3-S de 24 megapíxeles con rendimiento y vídeo mejorados en comparación con su predecesora. SL2-S. Es muy similar a uno de 60 megapíxeles enfocado en imagen. El SL3 se presentó en marzo del año pasado.pero está dirigido a usuarios híbridos que toman fotografías y vídeos. En cuanto a especificaciones, es similar a Panasonic. $2,200 T5 III Una cámara sin espejo puede utilizar un sensor similar.
La SL3-S con montura L tiene un cuerpo más grande que las cámaras de telémetro Leica a las que quizás esté acostumbrado. Ofrece diales delanteros y traseros para controlar las funciones principales, junto con un par de diales de modo, un joystick y varios botones más. Sin embargo, carece de algunos de los controles que se encuentran en modelos como el S5 IIX, por lo que es posible que tengas que profundizar en los menús para cambiar algunas configuraciones.
Leica
Afortunadamente, la pantalla táctil trasera es grande y de alta resolución (5,7 millones de puntos), aunque sólo se inclina y no se desplaza completamente, lo cual es desafortunado para una cámara híbrida. El visor electrónico (EVF) ofrece una resolución de 5,76 millones de puntos, que es sólida pero un poco baja en comparación con competidores de precio similar.
Una mejora importante es el enfoque automático más rápido, gracias al sensor BSI CMOS de fotograma completo de 24 MP. Esto permite disparos continuos de hasta 30 fps con AF de detección de fase continua, con tiempos de captura bastante largos gracias a la compatibilidad con tarjetas de memoria CFexpress tipo B rápidas. La compañía también promete 15 pasos de rango dinámico que deberían permitir ajustes más precisos al grabar archivos RAW.
Leica
Otra característica nueva importante está en el lado del video, con grabación de “apertura de puerta” 6K 3:2 (5952 x 3968 para ser precisos), o RAW de 10 bits 5888 x 3312 (para una grabadora externa), junto con 4K 60p. El SL3-S también admite grabación ProRes en dispositivos USB-C o tarjetas CFexpress B (no está claro si se admite la grabación de video RAW interna, aunque la hoja de especificaciones de. Vídeo de fotos de B&H Demuestra que ese es el caso.) Estas especificaciones de video corresponden estrechamente con el S5 IIX de Panasonic, aunque este último carece de una ranura para tarjeta CFexpress.
La principal ventaja de la cámara Leica son sus lentes Leica nítidos (y costosos), aunque la SL3-S también puede usar vidrio de los socios L-Mount, Panasonic y Sigma. La única gran ventaja sobre el S5 IIx es la adición de una ranura para tarjeta CFexpress, pero por lo demás, los dos modelos tienen especificaciones similares, por lo que si el Leica red dot vale los $3,100 adicionales es decisión de los compradores. El SL3-S de Leica ya está a la venta por 5.295 dólares Vídeo de fotos de B&H Y en otros lugares.
MLflow ha sido identificada como la plataforma de aprendizaje automático de código abierto más vulnerable
Las fallas en el recorrido del directorio permiten el acceso no autorizado a archivos en Weave
Los problemas de control de acceso a ZenML Cloud permiten riesgos de escalada de privilegios
Un análisis reciente del panorama de seguridad para los marcos de aprendizaje automático (ML) ha revelado que el software de ML está sujeto a más vulnerabilidades que categorías más maduras como DevOps o servidores web.
La creciente adopción del aprendizaje automático en todas las industrias resalta la necesidad crítica de proteger los sistemas de aprendizaje automático, ya que las vulnerabilidades pueden provocar acceso no autorizado, filtraciones de datos y operaciones comprometidas.
el un informe Desde JFrog afirma que los proyectos de aprendizaje automático como MLflow han experimentado un aumento en las vulnerabilidades críticas.En los últimos meses, JFrog ha expuesto 22 vulnerabilidades en 15 proyectos de aprendizaje automático de código abierto. Entre estas vulnerabilidades, se destacan dos categorías: amenazas dirigidas a componentes del lado del servidor y riesgos de escalada de privilegios dentro de marcos de aprendizaje automático.
Debilidades críticas en los marcos de aprendizaje automático
Las vulnerabilidades identificadas por JFrog afectan a componentes clave que se utilizan a menudo en los flujos de trabajo de aprendizaje automático, lo que podría permitir a los atacantes explotar herramientas en las que los profesionales del aprendizaje automático a menudo confían debido a su flexibilidad, para obtener acceso no autorizado a archivos confidenciales o escalar privilegios dentro de entornos de aprendizaje automático.
Una vulnerabilidad notable involucra Weave, un popular conjunto de herramientas de Weights & Biases (W&B), que ayuda a rastrear y visualizar las métricas del modelo de aprendizaje automático. La vulnerabilidad WANDB Weave Directory Traversal (CVE-2024-7340) permite a usuarios con pocos privilegios acceder a archivos arbitrarios a través del sistema de archivos.
Esta falla surge debido a una validación de entrada incorrecta al tratar con rutas de archivos, lo que podría permitir a los atacantes ver archivos confidenciales que pueden incluir claves API de administrador u otra información privilegiada. Una infracción de este tipo podría provocar una escalada de privilegios, dando a los atacantes acceso no autorizado a los recursos y comprometiendo la seguridad de todo el proceso de aprendizaje automático.
ZenML, una herramienta para gestionar canalizaciones MLOps, también se ve afectada por una vulnerabilidad crítica que amenaza sus sistemas de control de acceso. Esta falla permite a los atacantes con privilegios de acceso mínimos elevar sus permisos dentro de ZenML Cloud, una implementación administrada de ZenML, y así acceder a información restringida, incluidos secretos confidenciales o archivos modelo.
Suscríbase al boletín TechRadar Pro para recibir las principales noticias, opiniones, características y orientación que su empresa necesita para tener éxito.
El problema del control de acceso en ZenML expone el sistema a riesgos importantes, ya que los privilegios escalados podrían permitir a un atacante manipular los canales de aprendizaje automático, alterar los datos del modelo o acceder a datos operativos confidenciales, lo que podría afectar los entornos de producción que dependen de estos canales.
Se ha encontrado otra vulnerabilidad grave, conocida como inyección de comandos de Deep Lake (CVE-2024-6507), en la base de datos de Deep Lake, una solución de almacenamiento de datos optimizada. Amnistía Internacional Aplicaciones. Esta vulnerabilidad permite a los atacantes ejecutar comandos arbitrarios explotando la forma en que Deep Lake maneja las importaciones de conjuntos de datos externos.
Debido a una desinfección inadecuada de los comandos, un atacante podría ejecutar código de forma remota, comprometiendo la seguridad de la base de datos y de cualquier aplicación conectada.
También se encontró una vulnerabilidad notable en Vanna AI, una herramienta diseñada para la generación y visualización de consultas SQL en lenguaje natural. Vanna.AI Prompt Inyección (CVE-2024-5565) permite a los atacantes inyectar código malicioso en notificaciones SQL, que la herramienta procesa posteriormente. Esta vulnerabilidad, que puede conducir a la ejecución remota de código, permite a actores malintencionados apuntar a la función de visualización SQL-to-Graph de Vanna AI para manipular visualizaciones, realizar inyección SQL o filtrar datos.
Se descubrió que Mage.AI, una herramienta MLOps para administrar canalizaciones de datos, tiene múltiples vulnerabilidades, incluido el acceso no autorizado al shell, fugas de archivos arbitrarios y comprobaciones de recorrido de ruta débiles.
Estos problemas permiten a los atacantes tomar el control de las canalizaciones de datos, exponer configuraciones confidenciales o incluso ejecutar comandos maliciosos. La combinación de estas vulnerabilidades presenta un riesgo significativo de escalada de privilegios y violaciones de la integridad de los datos, lo que compromete la seguridad y la estabilidad de los canales de aprendizaje automático.
Al obtener acceso administrativo a bases de datos o registros de aprendizaje automático, los atacantes pueden incrustar código malicioso en los formularios, lo que genera puertas traseras que se activan cuando se carga el formulario. Esto puede poner en riesgo los procesos posteriores, ya que diferentes equipos y canales de CI/CD utilizan los modelos. Los atacantes también pueden filtrar datos confidenciales o realizar ataques de envenenamiento de modelos para reducir el rendimiento del modelo o manipular la salida.
Los hallazgos de JFrog resaltan una brecha operativa en la seguridad de las operaciones de los MLO. Muchas organizaciones carecen de una sólida integración de las prácticas de seguridad de IA y aprendizaje automático con estrategias de ciberseguridad más amplias, lo que genera posibles puntos ciegos. A medida que el aprendizaje automático y la inteligencia artificial continúan impulsando avances significativos en la industria, proteger los marcos, conjuntos de datos y modelos que impulsan estas innovaciones se vuelve primordial.
YouTube El martes, anunció la expansión de su función de doblaje automático para incluir contenido centrado en el conocimiento y la información. La plataforma de transmisión de video anunció por primera vez esta función en VidCon el año pasado y la está aprovechando. inteligencia artificial (Inteligencia Artificial) desarrollada por Aloud – Google El espacio interno es de 120 incubadoras. Como sugiere el nombre, el doblaje automático puede transcribir y traducir automáticamente videos de YouTube del inglés a otros dialectos y viceversa, lo que ayuda a los creadores de contenido a atraer espectadores que no hablan el mismo idioma al sortear las barreras del idioma.
Función de doblaje automático de YouTube ampliada
YouTube detalló la disponibilidad ampliada de su función de doblaje automático impulsada por IA en una publicación de blog. correo. La plataforma propiedad de Google dice que cientos de miles de canales de YouTube que forman parte del Programa de socios de YouTube y que se centran en el conocimiento y la información podrán aprovechar esta función.
Los creadores que crean vídeos en inglés pueden doblarlos automáticamente al francés, alemán, hindi, indonesio, italiano, japonés, portugués y español. Mientras tanto, si el vídeo está en alguno de los idiomas anteriores, será doblado al inglés. Los vídeos doblados usando esta función aparecerán con una etiqueta. Doblado automáticamente adjunto. Los espectadores pueden optar por escuchar el audio original utilizando el selector de pistas.
Para utilizar esta función, no se requieren pasos especiales. Los creadores simplemente necesitan subir videos y YouTube detectará automáticamente su idioma y los nombrará como otros idiomas admitidos. Los vídeos doblados se pueden ver en YouTube Studio en Idiomas dividir. Los creadores tendrán control sobre el doblaje y podrán optar por anular la publicación o eliminar los doblajes que no sean de su agrado, según la plataforma.
La compañía reconoce que puede haber casos en los que la traducción sea ligeramente incorrecta o el audio doblado no coincida con el hablante original. Sin embargo, enfatiza que los usuarios siempre pueden enviar comentarios para mejorar la función. Está trabajando para ofrecer un habla más precisa, expresiva y natural en el doblaje a través de una función llamada Expressive Speech que se presentó en una vista previa en el evento Made on YouTube en septiembre.
Los ganadores fueron anunciados por la Real Academia Sueca de Ciencias en Estocolmo.Fotografía: Jonathan Nackstrand/AFP vía Getty
Dos investigadores han desarrollado herramientas para comprender las redes neuronales que sustentan las redes actuales Un gran avance en inteligencia artificial (IA) Ganó el Premio Nobel de Física 2024.
John Hopfield de la Universidad de Princeton en Nueva Jersey y Geoffrey Hinton de la Universidad de Toronto en Canadá comparten el premio de 11 millones de coronas suecas (un millón de dólares estadounidenses), que fue anunciado por la Real Academia Sueca de Ciencias en Estocolmo el 8 de octubre.
Ambos utilizaron herramientas de la física para idear métodos que tengan este poder. Redes neuronales artificialesque explota estructuras de clases inspiradas en el cerebro para aprender conceptos abstractos. Sus descubrimientos “forman los componentes básicos de Aprendizaje automático“Podría ayudar a los humanos a tomar decisiones más rápidas y confiables”, dijo durante el anuncio Elin Munz, presidenta del Comité Nobel y física de la Universidad de Karlstad en Suecia. “Las redes neuronales artificiales se han utilizado para avanzar en la investigación de diversos temas de física, como la física de partículas, la ciencia de los materiales y la astrofísica”.
Memoria de la máquina
En 1982, Hopfield, Biólogo teórico con formación en física, vino con una red Describir las conexiones entre neuronas virtuales como fuerzas físicas.1. Al almacenar los patrones como un estado de bajo consumo de energía de la red, el sistema puede recrear el patrón cuando se le solicita algo similar. Se la conoce como memoria asociativa, porque la forma en que “recuerdas” las cosas es similar a cuando el cerebro intenta recordar una palabra o concepto basándose en información relacionada.
Hinton, un científico informático, utilizó principios de la física estadística, que describen colectivamente sistemas que tienen demasiadas partes para ser rastreados individualmente, para desarrollar aún más la “red Hopfield”. Al incorporar probabilidades en una versión multicapa de la red, creó una herramienta que podía reconocer y clasificar imágenes, o crear nuevos ejemplos del tipo en el que fue entrenada.2.
Informática: máquinas de aprendizaje
Estos procesos difieren de los tipos de computación anteriores, donde las redes podían aprender de ejemplos, incluidos datos complejos. Este fue un desafío para los programas tradicionales que se basaban en cálculos paso a paso.
Las redes son “modelos altamente idealizados que son tan diferentes de las redes neuronales biológicas reales como las manzanas lo son de los planetas”, dice Hinton. el escribio en naturalezaneurología En 2000. Pero ha demostrado ser útil y se ha aprovechado ampliamente. Las redes neuronales que imitan el aprendizaje humano forman la base de muchas herramientas modernas de inteligencia artificial, desde grandes modelos de lenguaje (LLM) hasta algoritmos de aprendizaje automático capaces de analizar grandes conjuntos de datos, incluidos Modelo de predicción de la estructura de la proteína AlphaFold.
Hablando por teléfono cuando se anunció el premio, Hinton dijo que enterarse de que había ganado el Premio Nobel fue “un rayo caído del cielo”. “Estoy sorprendido, no tenía idea de que esto sucedería”, dijo. Añadió que los avances en el aprendizaje automático “tendrán un impacto enorme y será similar a la revolución industrial”. Pero en lugar de superar a las personas en fuerza física, las superará en capacidad intelectual.
En los últimos años, Hinton se ha convertido en una de las voces más fuertes que piden salvaguardias en torno a la inteligencia artificial. Dice que el año pasado se convenció de que la computación digital era mejor que el cerebro humano, gracias a su capacidad de compartir el aprendizaje de múltiples copias de un algoritmo, ejecutándose en paralelo. “Hasta ese momento, había pasado 50 años pensando que si pudiéramos hacerlo más parecido a un cerebro, sería mejor”, dijo el 31 de mayo en una charla virtual en la Cumbre Mundial sobre Inteligencia Artificial para el Bien en Ginebra. Suiza. . “Me hizo pensar [these systems are] “Vamos a volvernos más inteligentes de lo que pensamos antes de lo que pensaba”.
Motivado por la física
Hinton también ganó el premio Alan Turing en 2018. A veces descrito como un “premio de informática”.. Hopfield también ha ganado muchos otros premios prestigiosos en física, incluida la Medalla Dirac.
“[Hopfield’s] “La motivación fue realmente la física, y este modelo de física se inventó para comprender determinadas fases de la materia”, afirma Karl Janssen, físico del Laboratorio Alemán de Sincrotrón (DESY) en Zeuthen, que describe el trabajo como “pionero”. Janssen añade que después de décadas de desarrollo, las redes neuronales se han convertido en una herramienta importante para analizar datos de experimentos de física y comprender los tipos de transiciones de fase que Hopfield se propuso estudiar.
Cómo ganar un Premio Nobel: ¿Qué tipo de científicos ganan medallas?
Lenka Zdeborova, física estadística computacional del Instituto Federal Suizo de Tecnología en Lausana (EPFL), dice que le sorprendió gratamente que el Comité del Nobel reconociera la importancia de las ideas de la física para comprender sistemas complejos. “Esta es una idea muy general, ya sean moléculas o personas en la sociedad”.
Ambos ganadores “aportan ideas muy importantes desde la física a la inteligencia artificial”, dice Yoshua Bengio, el científico informático que compartió el Premio Turing 2018 con Hinton y el también pionero de las redes neuronales Yann LeCun. El trabajo fundamental de Hinton y su contagioso entusiasmo lo convirtieron en un gran modelo a seguir para Bengio y otros de los primeros defensores de las redes neuronales. “Me sentí increíblemente inspirado cuando era estudiante”, dice Bengio, director del Instituto de Algoritmos de Aprendizaje de Montreal en Canadá. Muchos científicos informáticos habían considerado que la red neuronal era improductiva durante décadas, y un importante punto de inflexión se produjo cuando Hinton y otros la utilizaron para ganar un importante concurso de reconocimiento de imágenes en 2012, dice Bengio.
Beneficios del modelo cerebral
La biología también se ha beneficiado de estos modelos artificiales del cerebro. May-Britt Moser es una neurocientífica galardonada de la Universidad Noruega de Ciencia y Tecnología en Trondheim. Premio Nobel de Fisiología o Medicina 2014Ella dice que estaba “muy feliz” cuando vio anunciar a los ganadores. Ella dice que las versiones de los modelos de red de Hopfield han sido útiles para los neurocientíficos al investigar cómo las neuronas trabajan juntas en la memoria y la navegación. Añade que su modelo, que describe los recuerdos como puntos bajos en la superficie, ayuda a los investigadores a imaginar cómo ciertos pensamientos o miedos pueden arreglarse y recuperarse en el cerebro. “Me gusta usar esto como metáfora para hablar con la gente cuando está estancada”.
Diez códigos informáticos que cambiaron la ciencia
Hoy en día, la neurociencia se basa en teorías de redes y herramientas de aprendizaje automático, que surgieron del trabajo de Hopfield y Hinton, para comprender y procesar datos de miles de células simultáneamente, dice Moser. “Alimenta la comprensión de cosas con las que ni siquiera podíamos soñar cuando comenzamos en este campo”.
“El uso de herramientas de aprendizaje automático tiene un impacto inmensurable en el análisis de datos y en nuestra posible comprensión de cómo los circuitos cerebrales realizan cálculos”, dice Eve Marder, neurocientífica de la Universidad Brandeis en Waltham, Massachusetts. “Pero estos impactos quedan eclipsados por los muchos impactos que el aprendizaje automático y la inteligencia artificial están teniendo en todos los aspectos de nuestra vida diaria”.
¿Cuáles son las principales cosas que hace un ingeniero de aprendizaje automático moderno?
Parece una pregunta fácil con una respuesta sencilla:
Cree modelos de aprendizaje automático y analice datos.
De hecho, esta respuesta muchas veces no es correcta.
Uso efectivo de Datos La recopilación de datos es esencial para el éxito de cualquier negocio moderno. Sin embargo, convertir los datos en resultados comerciales tangibles requiere un viaje. Deben adquirirse, compartirse de forma segura y analizarse en su propio ciclo de vida de desarrollo.
Explosión Computación en la nube A mediados de la década de 2000, y las empresas adoptaron el aprendizaje automático una década después, este viaje abordó efectivamente un principio y un final. Pero desafortunadamente, las empresas a menudo enfrentan obstáculos intermedios relacionados con la calidad de los datos, que normalmente no están en el radar de la mayoría de los ejecutivos.
Oliver Gordon
Consultor de Soluciones en Atacama.
Cómo afecta la mala calidad de los datos a las empresas
Los datos de mala calidad e inutilizables son una carga para quienes han llegado al final del viaje de los datos. Estos son los usuarios de los datos que los utilizan para construir modelos y contribuir a otras actividades generadoras de beneficios.
Suscríbase al boletín TechRadar Pro para recibir todas las noticias, opiniones, funciones y orientación que su empresa necesita para tener éxito.
A menudo, se contrata a científicos de datos para crear modelos de aprendizaje automático y analizar datos, pero los datos incorrectos les impiden hacer algo así. Las organizaciones ponen mucho esfuerzo y cuidado en acceder a estos datos, pero a nadie se le ocurre comprobar si los datos que entran “en” el formulario son utilizables. Si los datos de entrada son defectuosos, los modelos y análisis de salida también lo serán.
Se estima que los científicos de datos dedican entre el 60 y el 80 por ciento de su tiempo a garantizar que los datos se limpien, para que los resultados de sus proyectos sean confiables. Este proceso de limpieza puede implicar adivinar el significado de los datos e inferir lagunas, y pueden descartar sin darse cuenta datos potencialmente valiosos de sus modelos. El resultado es frustrante e ineficiente porque estos datos sucios impiden que los científicos de datos hagan la parte valiosa de su trabajo: resolver problemas comerciales.
Este coste enorme, y a menudo invisible, ralentiza los proyectos y reduce sus resultados.
El problema se agrava cuando las tareas de limpieza de datos se realizan en silos repetitivos. El hecho de que una persona haya notado un problema en un proyecto y lo haya abordado no significa que haya logrado resolver el problema para todos sus colegas y sus proyectos.
Incluso si el equipo de ingeniería de datos puede realizar una limpieza exhaustiva, es posible que no pueda hacerlo de inmediato y que no comprenda completamente el contexto de la tarea y por qué lo está haciendo.
El impacto de la calidad de los datos en el aprendizaje automático
Los datos limpios son especialmente importantes para los proyectos de aprendizaje automático. Ya sean clasificaciones o regresión, aprendizaje supervisado o no supervisado, redes neuronales profundas o cuando un modelo de aprendizaje automático entra en una nueva fase de producción, sus creadores deben evaluar constantemente en función de nuevos datos.
Gestionar la distorsión de los datos para garantizar que el modelo sea eficaz y siga proporcionando valor empresarial es una parte esencial del ciclo de vida del aprendizaje automático. Después de todo, los datos son un panorama en constante cambio. Los sistemas fuente pueden consolidarse después de una adquisición, puede entrar en vigor una nueva gobernanza o puede cambiar el panorama empresarial.
Esto significa que es posible que las suposiciones anteriores de los datos ya no sean válidas. Si bien herramientas como Databricks/MLFlow, AWS Sagemaker o Azure ML Studio cubren la promoción, prueba y reentrenamiento de modelos de manera efectiva, son menos capaces de investigar qué parte de los datos cambió, por qué cambió y luego corregir los problemas, que pueden ser engorroso y largo.
Estar basado en datos evita que surjan estos problemas en los proyectos de aprendizaje automático, pero no son solo los equipos técnicos los que construyen los canales y los modelos; Más bien, requiere que toda la empresa esté alineada. Ejemplos de cómo esto puede surgir en la práctica son cuando los datos requieren un flujo de trabajo empresarial con alguien para su aprobación, o cuando una parte interesada no técnica en la oficina principal aporta conocimientos en las primeras etapas del recorrido de los datos.
El obstáculo para construir modelos de aprendizaje automático
Enumerar a los usuarios empresariales como Cliente El procesamiento de datos para sus organizaciones es cada vez más posible utilizando inteligencia artificial. El procesamiento del lenguaje natural permite a los usuarios no técnicos consultar datos y extraer información contextualmente.
Se espera que la tasa de crecimiento esperada de la inteligencia artificial entre 2023 y 2030 sea de alrededor del 37%. El 72% de los ejecutivos ve la inteligencia artificial como el principal impulsor un trabajo Se espera que en el futuro el 20 por ciento del EBITDA se genere para empresas maduras de IA.
La calidad de los datos es la columna vertebral de la IA. Mejora el rendimiento de los algoritmos y les permite producir predicciones, recomendaciones y clasificaciones confiables. Para el 33% de las empresas que informaron proyectos de IA fallidos, el motivo se debió a la mala calidad de los datos. De hecho, las organizaciones que se esfuerzan por lograr la calidad de los datos pueden impulsar una mayor eficacia de la IA en todos los ámbitos.
Pero la calidad de los datos no es sólo un elemento que se puede comprobar. Las organizaciones que lo convierten en una parte integral de sus operaciones pueden obtener resultados comerciales tangibles al generar más modelos de aprendizaje automático anualmente para obtener resultados comerciales más confiables y predecibles al brindar confianza en el modelo.
Cómo superar las barreras de la calidad de los datos
La calidad de los datos no debería consistir en esperar a que surja un problema en producción y luego apresurarse a solucionarlo. Más bien, los datos deberían probarse continuamente, dondequiera que residan, frente a un conjunto cada vez mayor de problemas conocidos. Todas las partes interesadas deben contribuir y todos los datos deben tener un propietario claro y bien definido. Entonces, cuando se le pregunta a un científico de datos qué hace, eventualmente podría decir: construir modelos de aprendizaje automático y analizar datos.
Este artículo se produjo como parte del canal Expert Insights de TechRadarPro, donde destacamos las mejores y más brillantes mentes de la industria tecnológica actual. Las opiniones expresadas aquí son las del autor y no reflejan necesariamente los puntos de vista de TechRadarPro o Future plc. Si está interesado en contribuir, obtenga más información aquí: https://www.techradar.com/news/submit-your-story-to-techradar-pro
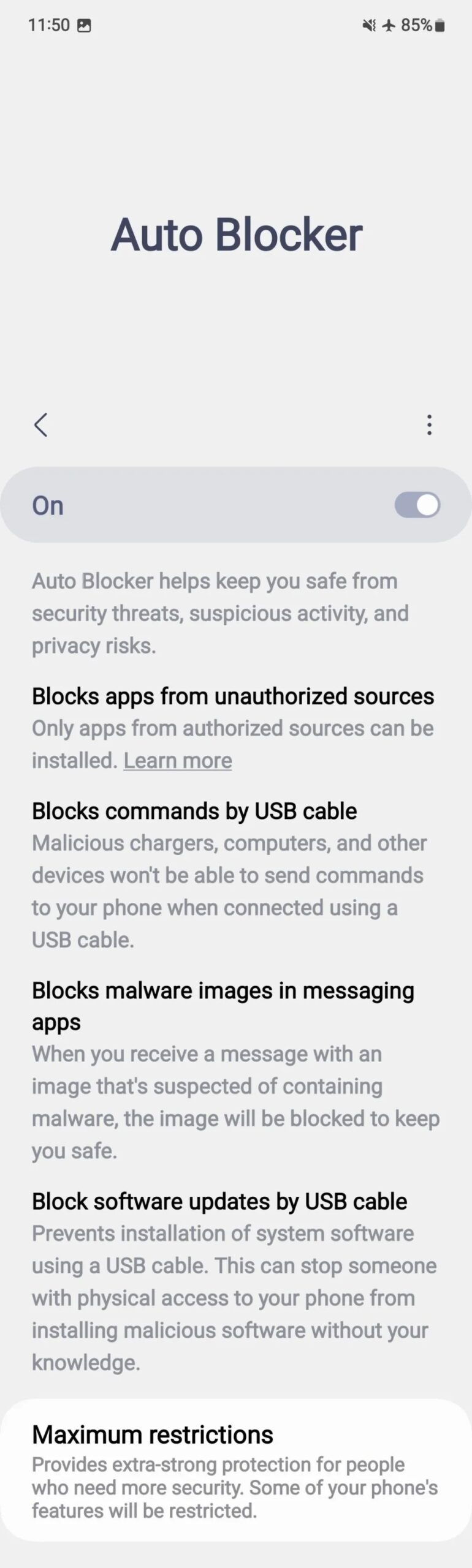
En los últimos años, Samsung ha mejorado constantemente la privacidad y seguridad de los datos en teléfonos y tabletas Galaxy. El año pasado presenté Nueva función llamada Bloqueador automático Lo que hizo que los dispositivos Galaxy fueran más seguros. Ahora la empresa está trabajando para mejorarlo a través de… Una interfaz de usuario 6.1.1.
One UI 6.1.1 mejora la función Auto Blocker para mayor seguridad
Bloquear aplicaciones de aplicaciones no autorizadas.
Bloquear comandos mediante cable USB.
Bloquear actualizaciones de software mediante cable USB.
Protección de aplicaciones de mensajería
Habilita las comprobaciones de seguridad de las aplicaciones.
En teléfonos que ejecutan One UI 6.0 o 6.1, puede habilitar o deshabilitar estas funciones individualmente. Y con One UI 6.1.1, Samsung eliminó la función (A través de la autoridad de Android) para habilitarlos o deshabilitarlos individualmente. Además, cuando desee desactivar la función de bloqueo automático, el teléfono le solicitará sus datos biométricos para autenticación.
Este método de autenticación adicional hace que su teléfono sea más seguro, ya que puede evitar que un atacante o una persona no deseada desactive fácilmente las medidas de seguridad de su teléfono.
Mire One UI 6.1.1 en el vídeo a continuación.
La función Análisis de seguridad de aplicaciones no es obligatoria en la nueva versión de Auto Blocker. Son parte del nuevo modo “Restricciones extremas”, que puedes activar o desactivar. Esta característica “Proporciona una protección extremadamente sólida para las personas que necesitan seguridad adicional.“Algunas funciones del teléfono no funcionarán cuando esta función esté habilitada. Estas funciones se enumeran a continuación.
Aplicaciones con acceso de administrador
Habilitar perfiles de trabajo
Álbumes compartidos
Compartir fotos usando GPS/datos de ubicación
Enlaces y vistas previas de enlaces
Crédito de la imagen: Samsung, Autoridad de Android
manzanas WatchOS 11 La actualización de los últimos modelos de Apple Watch de la compañía traerá nuevas funciones para mejorar la experiencia del usuario, anunció la compañía en el Congreso Mundial de Apple Watch. Conferencia mundial de desarrolladores (WWDC) 2024 lunes. Ahora, un usuario ha descubierto que una característica que Apple no mostró en la WWDC llegará al Apple Watch cuando llegue la actualización a finales de este año. Además, también se ha confirmado que la aplicación Smart Stack tendrá una herramienta Shazam dedicada, que permite a los usuarios buscar rápidamente las canciones que se están reproduciendo actualmente.
Con watchOS 11, los relojes inteligentes de Apple rastrearán automáticamente el ciclo de sueño de un usuario independientemente del modo del dispositivo, afirma Weinbach.
Con el reloj de manzanaLos usuarios pueden realizar un seguimiento de su ciclo de sueño y establecer horarios para lograr sus objetivos. Además, también se afirma que proporciona el tiempo estimado que pasa el usuario en cada etapa del sueño: sueño REM, sueño central y sueño profundo.
Apple también ofrece algo nuevo shazam Widget to Smart Stack: una colección de widgets inteligentes disponibles para los usuarios según la hora, la ubicación y la actividad a los que se puede acceder desde cualquier esfera del reloj.
Aunque Shazam ya estaba disponible en Tienda de aplicaciones O se puede acceder a través de siriSegún se informa, watchOS 11 lo llevará a Smart Stack, lo que podría permitir a los usuarios buscar más rápido la música que se está reproduciendo actualmente.
manzana Él dice Además de Shazam, también trae otras herramientas al Smart Stack, como traducción, distancia, fotografías, alertas de clima severo y actividades en vivo.
Compatibilidad con watchOS 11
Según Apple, watchOS 11 estará disponible en Apple Watch Series 6 o posterior, combinado con iPhone O los modelos más nuevos que estás usando iOS 18. La versión beta de watchOS 11 ya se lanzó para los desarrolladores y se puede acceder a ella a través del Programa de desarrolladores de Apple.
Los enlaces de afiliados pueden generarse automáticamente; consulte nuestro sitio web Declaración de ética Para detalles.
El seguimiento del sueño en Apple Watch ha mejorado mucho con watchOS 11. Imagen: watchOS 11 trae algunas mejoras de usabilidad notables.
WatchOS 11 Lleva el seguimiento automático del sueño al Apple Watch. Esto significa que el reloj inteligente puede realizar un seguimiento de su sueño incluso si no establece un horario de sueño ni utiliza el modo de suspensión. Modo de enfoque.
Aunque es un pequeño cambio, hace que el seguimiento del sueño en el Apple Watch sea más útil.
El seguimiento del sueño en Apple Watch mejorará mucho pronto
Actualmente, Apple requiere que ingreses un horario de sueño para garantizar que tu Apple Watch realice un seguimiento de tu sueño. También realizará un seguimiento de su sueño cuando se active el modo Sleep Focus. Sin embargo, el reloj sólo registra tus métricas de sueño durante este tiempo.
Por lo tanto, si te quedas dormido fuera de tu horario de sueño habitual o sin activar Sleep Focus, tus métricas de sueño no se registrarán. Esto significa que puede obtener información sobre su etapa de sueño, su nivel de oxígeno en sangre durante este período y más. Afortunadamente, watchOS 11 soluciona esta molesta limitación.
Max Weinbach Se dio cuenta de que su Apple Watch con watchOS 11 rastreaba su sueño aunque Focus on Sleep no estaba activado. Del mismo modo, no es necesario establecer un horario de sueño para que funcione el seguimiento.
Actualización: se puede confirmar y rastrea automáticamente las siestas https://t.co/AuzcULKusm
Es cierto que debes usar Sleep Focus mientras duermes para evitar que aparezcan notificaciones constantemente en tu Apple Watch. Pero si olvida habilitar Sleep Focus o su horario se complica, le alegrará saber que su Apple Watch seguirá registrando sus métricas de sueño.
watchOS 11 tiene varias mejoras centradas en la salud
El seguimiento del sueño mejorado en watchOS 11 viene junto con la nueva aplicación Vitals. Este último rastreará y mostrará sus métricas de salud clave: frecuencia cardíaca, respiración, temperatura, oxígeno en sangre y sueño. Aparecerá una advertencia si estas métricas exceden su rango típico. La aplicación también proporcionará información útil que puede afectar sus métricas de salud, como enfermedades o consumo de alcohol.
Google Según un informe, está probando una función de modo oscuro automático para sitios web en su aplicación para iPhone. Como sugiere el nombre, el informe sugiere que la función alterna automáticamente el modo oscuro en los sitios web relevantes. Al igual que un navegador, la aplicación de Google permite a los usuarios navegar por la web. Además, también cuenta con capacidades de inteligencia artificial (IA) a través de mellizo, el chatbot impulsado por IA de la empresa. Se dice que esta nueva característica se encuentra actualmente en prueba y no está ampliamente disponible para los usuarios.
Modo oscuro automático en iPhone
Según 9to5Google un informeel modo oscuro automático en iPhone estuvo disponible a través de Google Search Labs, un programa que permite a los usuarios probar funciones experimentales a las que el público aún no tiene acceso.
Según se informa, al implementar esta función, Google dijo: “Permanezca en modo oscuro sin importar el sitio web que navegue. Active el modo oscuro en su dispositivo para activar esta experiencia para que todos los sitios web que visite coincidan con el tema oscuro de su aplicación”.
Cuando esté habilitada, esta función se activará para todos los sitios web relevantes. También se menciona que el modo oscuro automático no estará disponible en sitios web que tengan un modo oscuro existente. En las capturas de pantalla compartidas por 9to5Google, el modo oscuro automático introdujo una nueva apariencia en el sitio web, pero no parece ofrecer una apariencia negra pura. En cambio, el fondo se volvió gris oscuro.
Dado que esta función actualmente sólo está disponible para los primeros probadores como prueba beta, se dice que Google dice: “La calidad de la conversión al modo oscuro puede variar. El experimento no se aplica a sitios web con el tema oscuro actual”.
Minimizar pestañas personalizadas en Chrome
Además de probar la función Modo oscuro automático en aplicación de googletambién un gigante tecnológico pie Hay una nueva función llamada Miniaturas de pestañas personalizadas cromo Navegador para Androide. Disponible con Chrome versión 124, convierte las pestañas en pequeñas ventanas flotantes cuando se minimizan.
Esta función aparece como un botón inferior en el banner superior junto al nombre del sitio. Al hacer clic en el botón, la pestaña se convierte en una ventana flotante de imagen en imagen (PiP).
Los enlaces de afiliados pueden generarse automáticamente; consulte nuestro sitio web Declaración de ética Para detalles.