OpenAI has introduced a new feature called GPT Mentions, which is in its beta stage and allows users to summon and interact with custom GPT agents within the chat interface. This feature is designed to enable a variety of tasks, such as saving entries to Notion via Zapier integration and more.
The release GPT Mentions follows on from other recent developments from OpenAI which are once again reshaping how we interact with ChatGPT in our daily lives. The new GPT Mentions feature rolled out by OpenAI to ChatGPT, is currently in beta testing. Yet already offers a significant advancement in the way AI is integrated into our routine tasks.
Enabling users to engage with custom GPT agents through a chat interface, making it easier to save information to applications like Notion. This is done through Zapier integration, which is a tool that connects different apps to automate tasks. The introduction of GPT Mentions is a testament to the growing role of AI in enhancing efficiency and user experience.
Zapier’s embrace of AI is particularly notable, with a significant portion of its workforce—30%—now relying on AI-powered workflows. The company’s partnership with OpenAI is a clear sign of the increasing collaboration between AI and workflow automation. As we explore the capabilities of GPT Mentions, it’s important to consider how this technology could revolutionize the way we work and boost our productivity.
OpenAI GPT Mentions

More information on creating AI automations using Zapier :
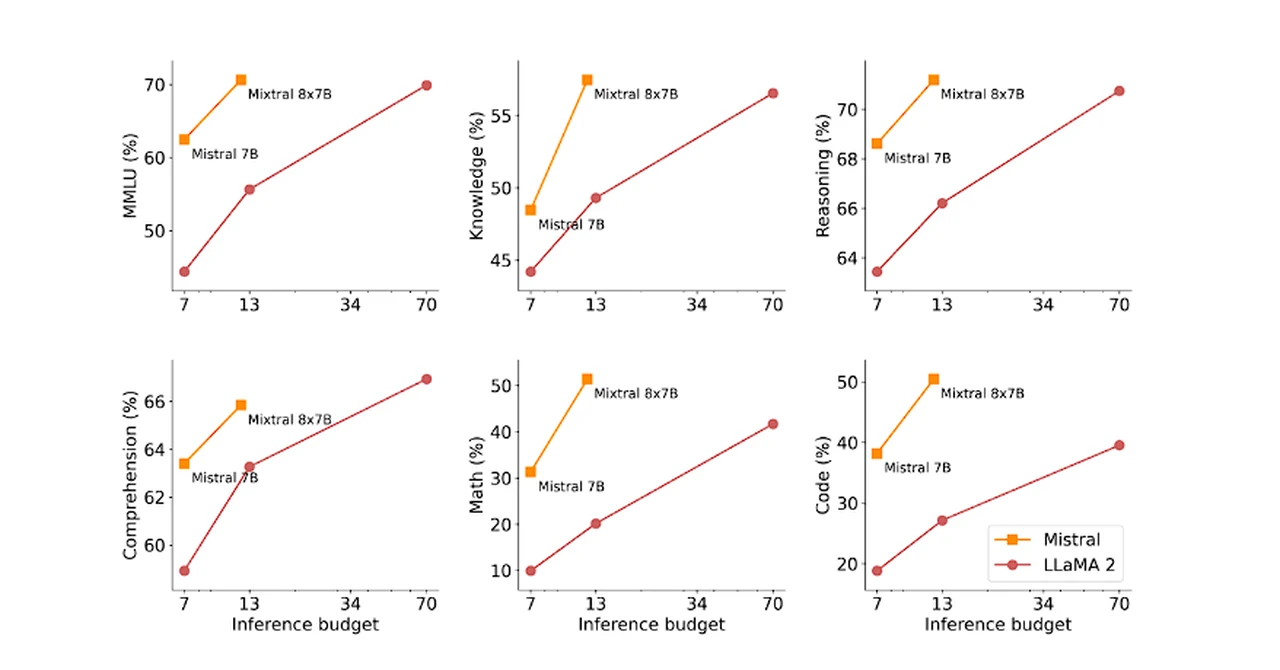
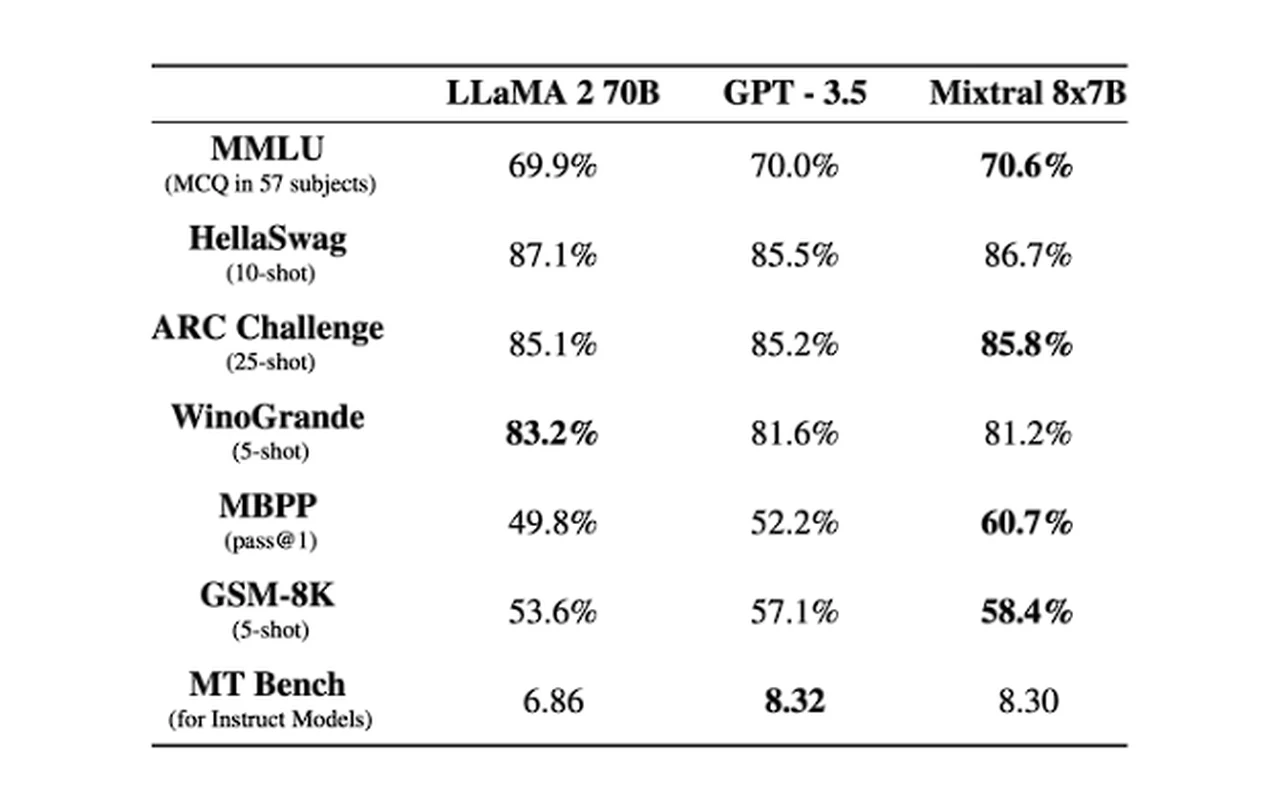
In the realm of internet browsing, the Brave browser has taken a step forward by incorporating the highly regarded open-source AI model Mixtral into its AI assistant, Leo. This integration is aimed at improving the online experience by summarizing web content and transcribing videos. It showcases the varied ways AI can enhance our interaction with digital content. Mixtral is now the default LLM for all Leo users, for the free version and the Premium version ($15/month). The free version is rate limited, and subscribers to Leo Premium benefit from higher rate limits.
Brave browser now features Mixtral
Brave Leo, powered by a blend of Mixtral 8x7B, Claude Instant, and Llama 2 13B, offers a multifaceted tool for content generation, summarization, language translation, and more. While it promises enhanced browsing efficiency and information accessibility, users should exercise discretion in verifying its outputs, mindful of the inherent limitations of current AI technologies.
“With today’s desktop browser update (v1.62), we are excited to announce that we have integrated Mixtral 8x7B as the default large language model (LLM) in Leo, our recently released, privacy-preserving AI browser assistant. Mixtral 8x7B is an open source LLM released by Mistral AI this past December, and has already seen broad usage due to its speed and performance. In addition, we’ve made several improvements to the Leo user experience, focusing on clearer onboarding, context controls, input and response formatting, and general UI polish.”

Here are some other articles you may find of interest on the subject of Mixtral 8x7B :
Brave is already using Mixtral for its newly released Code LLM feature for programming-related queries in Brave Search, and the combination of Mixtral’s performance with its open source nature made it a natural fit for integration in Leo, given Brave’s commitment to open models and the open source community.
Brave Leo, an innovative feature in the Brave browser, stands out due to its integration of cutting-edge language models. It utilizes a trio of models: Mixtral 8x7B, Claude Instant, and Llama 2 13B. Each of these models brings unique strengths, making Leo versatile in handling various tasks.
Mixtral 8x7B, part of Leo’s arsenal, excels in generating and summarizing content. This model is adept at condensing information, a skill particularly useful when users seek summaries of lengthy webpages or documents. Its ability to distill complex information into concise, digestible formats is a key asset in today’s information-heavy digital landscape.
Claude Instant, another model employed by Brave Leo, is designed for speed and efficiency. This model is particularly suited for rapid question-answering and quick clarifications. When users have specific queries or need fast explanations while browsing, Claude Instant steps in to provide prompt responses.
Llama 2 13B, the third model in the mix, enhances Leo’s multilingual capabilities. It facilitates seamless translation between different languages, catering to a global user base. This feature is vital in an interconnected world, enabling users to access and understand content in multiple languages.
Brave Leo’s AI-driven capabilities extend beyond these foundational tasks. It can create content, offering users assistance in drafting texts or generating ideas. Furthermore, its ability to transcribe audio and video expands its utility, making it a tool not just for text-based interactions but also for multimedia content. The inclusion of back-and-forth conversational abilities signifies a move towards more natural, human-like interactions with technology.
Regarding accessibility, Brave Leo is available on desktop platforms like macOS, Windows, and Linux, with plans to expand to mobile platforms. This broad availability ensures a wide range of users can benefit from its capabilities.
However, users should be aware of certain limitations and considerations. Brave Leo, like all AI models, may sometimes produce responses with factual inaccuracies or biased content, reflecting the limitations of current AI technology. Users are advised to verify the information provided by Leo and report any issues.
In terms of privacy and data handling, Brave Leo operates with a commitment to user confidentiality. Conversations are not stored or used for model training, addressing privacy concerns that are paramount in today’s digital environment. This approach aligns with the increasing emphasis on data security and user privacy in the digital age.
Other AI news
Another development to keep an eye on is the partnership between Google and Hugging Face. This collaboration is focused on enhancing the open-source AI platform, aiming to foster innovation and make it more accessible to a wider audience. Such partnerships underscore the collaborative spirit that is propelling the AI industry forward.
Lucid Dreaming
On the experimental front, there’s the creation of Morpheus One, a multimodal generative ultrasound transformer created by Prophetic AI that delves into the fascinating realm of lucid dreaming. With beta testing anticipated in spring 2024, this technology offers the potential for groundbreaking research into dream analysis and manipulation.
OpenAI’s GPT Mentions offer a new way to integrate with the OpenAI platform through the integration of AI in tools like Zapier, the enhancement of web browsing with Brave’s Mixtral AI model, the ethical considerations arising from LLM research, or the latest breakthroughs and collaborations in AI, these developments are reshaping the technological landscape. It’s crucial to stay informed about these advancements, as they are not only transforming how we interact with digital platforms but also pushing the boundaries of what we once thought was possible.
Image Credit : Brave
Filed Under: Technology News, Top News
Latest timeswonderful Deals
Disclosure: Some of our articles include affiliate links. If you buy something through one of these links, timeswonderful may earn an affiliate commission. Learn about our Disclosure Policy.