En muchos países hay más investigadores postdoctorales que puestos docentes disponibles.Crédito: Lanxi Wu/Alamy
Más del 40% de los investigadores postdoctorales abandonan la academia, según un estudio entre unos 45.500 investigadores1. Aquellos que se quedaron y consiguieron un puesto docente deseable tenían más probabilidades de tener un artículo muy citado, cambiar su tema de investigación entre doctorado y posdoctorado, o mudarse al extranjero después de obtener su doctorado.
El estudio publicado en Actas de la Academia Nacional de Ciencias El 20 de enero, observé a investigadores de todo el mundo que se habían presentado desde Doctor en Filosofía A un título posdoctoral (un puesto temporal para mayor capacitación profesional, desarrollo e investigación ampliada) y luego, en algunos casos, a un puesto docente. El estudio abarcó 25 años y 19 disciplinas académicas y utilizó datos deMicrosoft Academic Graph, una colección que contiene 257 millones de publicaciones. Los investigadores filtraron los datos utilizando una red profesional en línea (presumiblemente LinkedIn, aunque los autores no lo dijeron) para que coincidieran con el currículum del investigador.
Estudios anteriores se han centrado principalmente en la importancia que tiene el prestigio de las instituciones que otorgan doctorados para la permanencia del profesorado.2. Bodour Al-Shibli, socióloga computacional de la Universidad de Nueva York en Abu Dabi (Emiratos Árabes Unidos), y sus coautores querían llenar un vacío en la investigación e identificar la importancia de la formación postdoctoral para conseguir un puesto docente y el éxito inicial en la carrera.
“Nuestra investigación destaca que los años postdoctorales son tan importantes como los años de doctorado a la hora de evaluar la probabilidad de que un científico ingrese con éxito a la academia y obtenga un puesto docente”, dice.
Un camino hacia el éxito
En muchos países hay más investigadores postdoctorales. Empleos de la facultad disponible. Esto crea un cuello de botella. El conjunto de datos del equipo muestra que el 41% de los postdoctorados terminan haciéndolo dejar la academia. Los investigadores que publican menos artículos durante su posdoctorado que durante su doctorado tienen más probabilidades de irse, dice Al-Shibli.
Para los investigadores comprometidos, ¿qué define el éxito? Para responder a esta pregunta, el equipo desarrolló una medida de la producción científica, llamada o-index – como alternativa al éxito. Esta medida se basa en el índice h, el número de citas de un investigador, pero se centra únicamente en artículos publicados entre dos y cuatro años después de obtener un puesto docente.
Los autores cuyos artículos fueron retractados dijeron que los errores en sus datos se debían principalmente a falta de atención o problemas técnicos.Crédito: Jacob Wackerhausen/Getty
La mayoría de los investigadores cuyos artículos se retractan debido a un error involuntario encuentran estresante la terrible experiencia, según una encuesta realizada a casi 100 autores.1.
La encuesta se centró en los retrocesos que se produjeron debido a errores en la gestión de datos, una causa común. Casi la mitad de los encuestados dijeron que el retiro les causó un estrés extremo (ver “La experiencia del autor”).
Fuente: Referencia. 1
Los hallazgos brindan una visión detallada de las circunstancias, además de la mala conducta que condujo a las retractaciones y el costo emocional que el proceso tuvo en los investigadores, un tema rara vez discutido en las publicaciones científicas, dice Misha Angrist, investigadora de políticas científicas que ha estudiado las retractaciones. en la Universidad de Duke en Durham, Carolina del Norte. “Es una adición realmente útil a la literatura”, afirma.
Muchas retractaciones están relacionadas con fraude y mala conducta, y estos casos suelen recibir mucha atención, pero los estudios han demostrado que las retractaciones debidas a errores honestos también son comunes.2. Estos análisis se han basado en gran medida en avisos de retractación, que pueden carecer de detalles específicos sobre el error y su causa, dice el coautor del estudio Marton Kovacs, investigador de metaciencia de la Universidad Eötvös Loránd de Budapest. “Rara vez se encuentra información sobre la naturaleza humana de estos errores”, dice Kovacs.
Abundan los errores
Para abordar esta brecha, Kovacs y sus colegas utilizaron la base de datos Retraction Watch; Identificar 5.041 trabajos de investigación que fueron retractados por errores en el manejo de datos.
Los investigadores enviaron una encuesta por correo electrónico a 6.680 autores de estos estudios, preguntándoles sobre los errores y qué pensaban que los causaba. Casi 250 investigadores respondieron y, tras eliminar a los que no respondieron todas las preguntas, el equipo se quedó con 97 respuestas. Los resultados fueron publicados el mes pasado en Ciencia abierta de la Royal Society.
Los investigadores identificaron 18 tipos de errores en el manejo de datos. El error más común fue el procesamiento y análisis de datos incorrectos, como usar una fórmula incorrecta o calcular mal una estadística; Este error se informó en 16 respuestas, lo que representa aproximadamente el 20% de los errores. Los errores de codificación, la pérdida de material o datos y los incidentes de entrada se monitorean de cerca (consulte “Causa de los errores”).
Meta planea deshacerse de su programa de verificación de datos de terceros en favor de “comentarios de la comunidad” tipo X. Crédito: Yue Mok/PA Images vía Getty
Se dice que una mentira puede volar alrededor del mundo mientras la verdad se pone los zapatos. Este viaje para desafiar las mentiras y la desinformación en línea se volvió más difícil esta semana, cuando Meta, la empresa matriz de Facebook, anunció planes para eliminar el programa de verificación de datos de la plataforma, que se creó en 2016 y paga a grupos independientes para verificar artículos y publicaciones seleccionados.
La compañía dijo que este paso tiene como objetivo confrontar el sesgo político y la censura practicada por los verificadores de datos. “Los expertos, como todos los demás, tienen sus propios prejuicios y puntos de vista. Esto se ha demostrado en las decisiones que algunos han tomado sobre qué verificar y cómo verificarlo”, Joel Kaplan, director de asuntos globales de Meta. Escrito el 7 de enero.
naturaleza Hablé con investigadores de comunicaciones y desinformación sobre el valor de la verificación de hechos, de dónde provienen los sesgos percibidos y lo que podría significar una metadecisión.
Efecto positivo
En términos de ayudar a convencer a las personas de que la información es verdadera y confiable, “la verificación de hechos realmente funciona”, dice Sander van der Linden, psicólogo social de la Universidad de Cambridge en el Reino Unido, que trabajó como consultor no remunerado en la plataforma de Facebook. programa de verificación. en 2022. “Los estudios proporcionan evidencia muy consistente de que la verificación de hechos reduce al menos parcialmente los conceptos erróneos sobre afirmaciones falsas”.
Por ejemplo, un metanálisis de 2019 sobre la eficacia de la verificación de datos en más de 20.000 personas encontró un “efecto general positivo significativo en las creencias políticas”.1.
“Lo ideal es que la gente no se forme ideas erróneas”, añade van der Linden. “Pero si tenemos que lidiar con el hecho de que las personas ya están expuestas, reducirlo es lo mejor que podemos hacer”.
Lo que sabemos y lo que no sabemos sobre cómo se difunde la información errónea en línea
La verificación de hechos es menos efectiva cuando el tema está polarizado, dice Jay Van Bavel, psicólogo de la Universidad de Nueva York en la ciudad de Nueva York. “Si estás verificando algo sobre el Brexit en el Reino Unido o las elecciones en Estados Unidos, ahí es donde las verificaciones de hechos no funcionan bien”, dice. “En parte, eso se debe a que los partidistas no quieren creer cosas que hagan quedar mal a su partido”.
Pero incluso cuando las verificaciones de datos no parecen cambiar la opinión de las personas sobre temas controvertidos, aún pueden ser útiles, dice Alexios Mantzarlis, un ex verificador de datos que dirige la Iniciativa de Seguridad, Confianza y Protección en Cornell Tech en la ciudad de Nueva York. . .
En Facebook, los artículos y publicaciones considerados falsos por los verificadores de datos actualmente están marcados con una advertencia. También están expuestos a menos usuarios a través de los algoritmos de sugerencia de la plataforma, dice Manzarlis, y es más probable que las personas ignoren el contenido marcado en lugar de leerlo y compartirlo.
Marcar publicaciones como problemáticas también puede tener efectos en cadena en otros usuarios, algo que no ha sido captado por los estudios sobre la efectividad de la verificación de datos, dice Kate Starbird, científica informática de la Universidad de Washington en Seattle. “Medir el impacto directo de las etiquetas en las creencias y acciones de los usuarios es diferente de medir los efectos más amplios de realizar verificaciones de datos en el ecosistema de la información”, añade.
Más desinformación, más señales de alerta
Con respecto a las afirmaciones de Zuckerberg de parcialidad entre los verificadores de datos, Van Bavel está de acuerdo en que la información errónea proveniente de la derecha política se verifica y se señala como problemática (en Facebook y otras plataformas) con más frecuencia que la información errónea proveniente de la izquierda. Pero ofrece una explicación simple.
“Esto se debe en gran medida a que la desinformación conservadora es el material que más se difunde”, afirma. “Cuando un partido, al menos en Estados Unidos, difunde la mayor cantidad de información errónea, parecerá que las verificaciones de hechos están sesgadas porque se les denuncia más”.
En su forma más pura, Actuar es un juego extraño. De fingir. Si eres lo suficientemente bueno como para ganarte la vida con ello, vas a trabajar todos los días y te metes bajo la piel de un extraño. Puedes ser alguien tan inocente como un padre amoroso o tan malicioso como un asesino a sangre fría. El trabajo requiere que seas un maestro de la empatía; Puede que no te guste la persona que interpretas, pero debes entenderla lo suficientemente bien como para que tus deseos sean creíbles, si no identificables, para tu audiencia. Es un trabajo divertido y aterrador, y cuanto más te adentras en él, más difícil resulta salir del personaje.
Esto, por supuesto, depende de cómo enfoques el oficio. Si eres un actor de método capacitado Como Robert De Niroconviértete en tu personaje. Sin embargo, si eres un mitólogo experimentado y prefieres jugar el juego corto, puedes entrar y salir del personaje con poco esfuerzo psicológico. Aquí actuar se vuelve indistinguible de mentir. Este enfoque aún requiere el sentido básico de juego que poseen todos los actores, pero puede resultar inquietante para un extraño porque no hay aceptación emocional. En un momento, estás tentando sin esfuerzo a una persona casada a cometer adulterio, y una hora más tarde, estás fuera de tu elemento y regresas a casa para pasar el día.
Suena más a ser un investigador privado, ¿no? ¿Le sorprendería saber que dos de los actores más talentosos de los últimos 30 años han trabajado en esta profesión? Quizás no, pero descubrirás actores que han prosperado en esta industria.
¿Dónde se desarrolla la serie de detectives de Wayne Knight y Margo Martindale?
Forex
hace dos semanas, Creador de cómics Ryan Estrada Se volvió viral en Bluesky al informar a sus seguidores que Wayne Knight y Margo Martindale complementaron sus ingresos como actores trabajando en la misma agencia de detectives. Sí, Newman de Seinfeld y Tazas de “Mabarar” Usaron sus talentos de actuación para atrapar a personas deshonestas.
Según Knight, veía este trabajo como una actividad secundaria para evitar depender del desempleo. ¿Cómo llegaste a este tipo de trabajo? Como Knight le dijo a Vice en 2015:
“[I] Estaba atendiendo mesas como todos los demás cuando comencé. Y tenía un amigo que me dijo: “Bueno, tengo un trabajo que podría interesarte”. Dije: “¿Sí? ¿Qué es esto?” “Soy un investigador privado”, dice. Le dije: Usted no tiene antecedentes policiales, ¿fue entrenado para esto? 'No.' “¿Cómo te contrataron?” “Bueno, les gusta contratar actores porque normalmente son inteligentes, tienen conocimientos, pueden interpretar diferentes papeles y no tienen ningún escrúpulo”, dice.
La habilidad de Knight para las falacias le permitió hablar por teléfono y atrapar a maridos infieles y, de manera más ambiciosa, a jefes corporativos y personal militar de alto rango que buscaban ganar dinero en el mundo del capitalismo de riesgo. Usó el apodo de “Bill Monte” para mantener el truco el mayor tiempo posible y tuvo suficiente éxito como para intentar convertir estos experimentos en una comedia o una película durante las últimas décadas.
En cuanto a Martindale, estaba menos enamorada de la fiesta. Como dijo Backstory en 2020“Contrataron a muchos actores. Yo no tenía cosas interesantes que hacer, pero se trataba de extraer información de personas desprevenidas para cazatalentos, maridos celosos y esposas que admiraban a sus maridos con valentía”. Añadió que, si bien los hombres a veces salían al campo, las mujeres se quedaban atrapadas trabajando con los teléfonos. Si se va a hacer una película o serie a partir de esta mala historia, prefiero verla contada desde el punto de vista de Martindale.
En toda América Latina y Europa del Este, la gente vende intencionalmente sus documentos de identidad.
Las personas proporcionan voluntariamente fotografías y documentos a cambio de un pago.
Esta evolución del delito de uso indebido de la identidad hace que la detección de fraude estándar sea redundante
Los investigadores de iProov han descubierto una operación compleja en la web oscura destinada a socavar los controles de conocimiento de su cliente (KYC).
A diferencia de lo tradicional robo de identidadEl plan implica que víctimas desprevenidas entreguen voluntariamente sus documentos de identidad y fotografías faciales a cambio de una compensación financiera.
Este enfoque, llamado “cultivo de identidades”, permite a los delincuentes explotar credenciales reales para eludir los sistemas de verificación, lo que complica los esfuerzos de detección.
Explotar credenciales genuinas
Al recopilar credenciales reales, esta operación, que está activa principalmente en la región LATAM (América Latina), puede superar a los métodos tradicionales de verificación de documentos que destacan en la detección de falsificaciones o alteraciones.
Si bien se han observado actividades similares en Europa del Este, no se ha demostrado un vínculo directo entre los dos grupos.
En áreas que enfrentan dificultades económicas y altas tasas de desempleo, las personas están dispuestas a comprometer sus identidades para obtener ganancias financieras a corto plazo.
Los estafadores explotan a sus víctimas de esta manera, ofreciéndoles pagar por documentos de identidad y datos biométricos, a menudo con falsos pretextos. Muchas víctimas ven esto como una transacción de bajo riesgo.
Suscríbase al boletín informativo TechRadar Pro para recibir las principales noticias, opiniones, características y orientación que su empresa necesita para tener éxito.
¿Cómo funcionan los trasplantes de identidad?
Los atacantes son un grupo con habilidades mixtas. Los principiantes confían en técnicas sencillas y eficaces, como la presentación de imágenes fijas o vídeos pregrabados.
Los actores más sofisticados utilizan herramientas avanzadas como software de intercambio de rostros y manipulación de la iluminación, y los atacantes más capaces utilizan modelos de IA personalizados y animaciones 3D, diseñados para imitar el comportamiento humano natural en tiempo real.
Según iProov, se necesita una estrategia de varios niveles a la hora de proteger los sistemas de verificación de identidad.
Esto incluye medidas como verificar que la identidad proporcionada coincida con documentos oficiales, utilizar imágenes incrustadas y análisis de metadatos para confirmar la presencia de una persona real e implementar sistemas de respuesta a desafíos en tiempo real para detectar comportamientos fraudulentos.
“Lo que es particularmente preocupante de este descubrimiento no es sólo la naturaleza compleja del proceso, sino el hecho de que los individuos están comprometiendo voluntariamente sus identidades para obtener ganancias financieras a corto plazo”, dijo Andrew Newell, director científico de iProov.
“Cuando las personas venden sus documentos de identidad y datos biométricos, no sólo están arriesgando su seguridad financiera, sino que también están proporcionando a los delincuentes paquetes de identidad completos y reales que pueden ser utilizados en sofisticadas estafas de suplantación de identidad”.
“Estas identidades son particularmente peligrosas porque incluyen documentos reales y datos biométricos coincidentes, lo que las hace extremadamente difíciles de detectar mediante métodos de verificación tradicionales”.
Un equipo de investigadores ha propuesto una teoría convincente sobre misteriosos objetos binarios con la masa de Júpiter (Jumbo), arrojando luz sobre sus misteriosos orígenes. El estudio, publicado en The Astrophysical Journal en noviembre, profundiza en el proceso de “fotocorrosión” para explicar la formación de estos extraños cuerpos celestes.
Según declaraciones hechas a Space.com por Richard Parker, astrofísico de la Universidad de Sheffield, y la investigadora universitaria Jessica Diamond, los objetos masivos pueden haberse formado como núcleos estelares, pero fueron despojados de su masa por la intensa radiación de estrellas masivas. Esta visión podría revelar el secreto de cómo surgieron estos objetos, que fueron vistos por primera vez en 2023.
Descubrimiento de objetos gigantes en la Nebulosa de Orión
En 2023, Astrónomos usando Telescopio espacial James Webb Se han identificado 42 pares de objetos masivos en el cúmulo de la Nebulosa de Orión. A diferencia de las estrellas típicas o PlanetasEstos objetos flotaban libremente y existían en pares binarios, lo que generó controversia sobre su formación. La ausencia de una estrella madre y su persistencia como binarias contradice los modelos tradicionales de evolución planetaria y estelar, creando un enigma científico.
El papel de la erosión de la imagen.
Informes Sugiere que la teoría de Parker y Diamond se basa en la fotoerosión, un proceso en el que la radiación de estrellas masivas de tipo O y B destruye las capas externas de los núcleos estelares cercanos. Este fenómeno comprime el material restante, creando objetos gigantes con masas similares a las de algunos Júpiter. Parker confirmó a Space.com que estos objetos habrían sido estrellas típicas si no hubiera sido por la influencia de la radiación, que los convirtió en algo más cercano a las enanas marrones.
Observaciones futuras y validación.
Según la investigación, las regiones con radiación intensa deberían albergar JuMBO más pequeños, lo que proporcionaría una forma de probar esta hipótesis. La observación de regiones similares de formación de estrellas podría proporcionar más pruebas o cuestionar esta idea. Parker señaló que la vida útil de los objetos masivos puede ser corta en cúmulos muy poblados, lo que sugiere que observarlos representa una oportunidad fugaz para que los astrónomos los estudien.
Este estudio añade una nueva dimensión a la comprensión de los cuerpos celestes y proporciona una nueva perspectiva sobre los procesos de formación de estrellas y planetas en el universo.
Investigadores surcoreanos han construido un traje de exoesqueleto robótico portátil que podría ayudar a las personas con paraplejía a caminar nuevamente. El traje, llamado WalkON Suit F1, fue desarrollado por el equipo del Laboratorio de Exoesqueleto del Instituto Avanzado de Ciencia y Tecnología de Corea (KAIST). Los investigadores han construido varias versiones de dispositivos portátiles. robot Anteriormente era un casco externo, pero el modelo más nuevo viene con un mecanismo de acoplamiento frontal. También puede caminar y acercarse al usuario, lo que le valió el sobrenombre de traje de “Iron Man”.
El laboratorio de exoesqueleto de KAIST presenta el traje WalkON F1
en la sala de redacción correoLos investigadores revelaron el nuevo traje robótico con exoesqueleto, y destacaron que está especialmente diseñado para personas con hemiplejía (parálisis en las piernas y parte inferior del cuerpo) para ayudarles a caminar nuevamente. El equipo afirmó que el traje robótico puede caminar hacia el usuario y puede usarse mientras está sentado en una silla de ruedas, lo que lo hace accesible para todos sin necesidad de ayuda de otros.
Desarrollado en colaboración con Angel Robotics, el robot puede ayudar a las personas con la Escala de Deterioro de la Asociación Estadounidense de Lesiones Espinales (ASIA) para lesiones de Grado 1 (parálisis completa), el nivel más grave de paraplejía. Está diseñado como una ayuda para caminar y no está diseñado para usarse en terapia de rehabilitación o para mejorar la fuerza muscular.
El proyecto WalkON Suit F1 fue dirigido por el profesor Kyung-Chol Kong (CEO y fundador de Angel Robotics) del Departamento de Ingeniería Mecánica de KAIST. El modelo actual sigue al WalkON Suit 1, anunciado en 2016, y al WalkON Suit 4, que llegó en 2020.
La última versión resuelve muchos de los problemas que existían en sus predecesores. Específicamente, aborda el problema de los usuarios que necesitan ayuda de otros para usar el robot. Esto se debe a que los modelos anteriores tenían un mecanismo de asiento en la parte trasera. Alternativamente, el WalkON Suit F1 tiene un sistema de acoplamiento frontal que se puede usar mientras se está sentado en una silla de ruedas.
Además, el traje puede caminar como un robot y acercarse al usuario, eliminando la necesidad de que alguien lleve el traje exoesqueleto. El robot también controla activamente su centro de peso contra la gravedad para mantener el equilibrio incluso cuando el usuario empuja el robot. El diseño del robot portátil fue creado por el profesor Hyunjun Park del Departamento de Diseño Industrial de KAIST.
Con ello, los usuarios podrán caminar a una velocidad de 3,2 kilómetros por hora. Los usuarios también pueden mantener las manos libres mientras caminan, algo que no era posible en versiones anteriores. Además, el equipo afirma que el robot tiene la capacidad de atravesar obstáculos como pasillos estrechos, puertas y escaleras. Cabe destacar que el robot está fabricado en aluminio y titanio y pesa 50 kg.
Un nuevo estudio realizado por físicos del Instituto Tecnológico de Massachusetts tecnología (MIT) y colaboradores para medir la geometría cuántica de electrones en sólidos. La investigación proporciona información sobre la forma y el comportamiento de electrones Dentro de materiales cristalinos a nivel cuántico. Según el estudio, la ingeniería cuántica, que antes se limitaba a predicciones teóricas, se ha observado directamente, lo que ha permitido formas sin precedentes de manipular las propiedades de los materiales cuánticos.
Nuevos caminos para la investigación de materiales cuánticos
el el estudia Fue publicado en Nature Physics el 25 de noviembre. Según lo descrito por Ricardo Comin, profesor asociado de desarrollo profesional, promoción de 1947 Física En el MIT, el logro es un avance importante en la ciencia de materiales cuánticos. En una entrevista con el Laboratorio de Investigación de Materiales del MIT, Comin destacó que su equipo ha desarrollado un plan para obtener información completamente nueva sobre sistemas cuánticos. La metodología utilizada puede aplicarse a una amplia gama de Cantidad Materiales más allá de los probados en este estudio.
Las innovaciones técnicas permiten la medición directa
el investigación Los investigadores utilizaron espectroscopia de fotoemisión con resolución de ángulo (ARPES), una técnica que Komin y sus colegas habían utilizado anteriormente para examinar propiedades cuánticas. El equipo modificó ARPES para medir directamente la geometría cuántica en un material conocido como metal kagome, que tiene una estructura reticular con propiedades electrónicas únicas. Esta medición fue posible gracias a la colaboración entre experimentalistas y teóricos de múltiples instituciones, incluida Corea del Sur, durante la pandemia, señaló Minju Kang, primer autor del artículo y becario postdoctoral Kavli en la Universidad de Cornell.
Estos experimentos confirman los esfuerzos colaborativos y beneficiosos realizados para lograr este logro científico. Este avance ofrece nuevas posibilidades para comprender el comportamiento cuántico de los materiales, allanando el camino para innovaciones en informática, electrónica y tecnologías magnéticas, como informa la revista Nature Physics.
Investigadores chinos han modificado el modelo Meta Lama para uso de inteligencia militar
ChatBIT expone los riesgos de la tecnología de inteligencia artificial de código abierto
Meta se distancia de aplicaciones militares no autorizadas de LAMA
El modelo Llama AI de Meta es Código abierto Es de uso gratuito, pero los términos de licencia de la empresa establecen claramente el modelo.Diseñado únicamente para aplicaciones no militares.
Sin embargo, ha habido preocupaciones sobre cómo se verifica la tecnología de código abierto para garantizar que no se utilice para fines incorrectos, y las últimas especulaciones confirman la validez de estas preocupaciones, con informes recientes que afirman que investigadores chinos con vínculos con el Ejército Popular de Liberación ( PLA) han creado un modelo de IA centrado en el ejército llamado ChatBIT usando una llama.
El surgimiento de ChatBIT resalta el potencial y los desafíos de la tecnología de código abierto en un mundo donde el acceso a la inteligencia artificial avanzada se considera cada vez más una cuestión de seguridad nacional.
Un modelo chino de inteligencia artificial para la inteligencia militar
Un estudio reciente realizado por seis investigadores chinos de tres instituciones, incluidas dos asociadas con la Academia de Ciencias Militares (AMS) del Ejército Popular de Liberación, describe el desarrollo de ChatBIT, que se construyó utilizando una versión inicial del modelo Llama de Meta.
Al incorporar sus parámetros en el modelo de lenguaje grande Llama 2 13B, los investigadores pretendían producir una herramienta de inteligencia artificial centrada en el ejército. Los artículos académicos de seguimiento posteriores describen cómo se adaptó ChatBIT para manejar diálogos militares específicos y ayudar en las decisiones operativas, con el objetivo de funcionar a aproximadamente el 90% de la capacidad de GPT-4. Sin embargo, aún no está claro cómo se calcularon estas métricas de desempeño, ya que no se han revelado procedimientos de prueba detallados ni aplicaciones de campo.
Según se informa, analistas familiarizados con la inteligencia artificial y la investigación militar china revisaron estos documentos y respaldaron las afirmaciones sobre el desarrollo y la funcionalidad de ChatBIT. Afirman que las métricas de rendimiento informadas en ChatBIT son consistentes con aplicaciones experimentales de IA, pero señalan que la falta de métodos de medición claros o conjuntos de datos accesibles dificulta la confirmación de las afirmaciones.
Además, llevó a cabo una investigación Reuters Proporciona otra capa de apoyo, citando fuentes y analistas que han revisado materiales que vinculan a investigadores afiliados al Ejército Popular de Liberación de China con el desarrollo de ChatBIT. La investigación señala que estos documentos y entrevistas revelan los intentos del ejército chino de reutilizar un metamodelo de código abierto para misiones estratégicas y de inteligencia, lo que lo convierte en el primer ejemplo informado públicamente de un ejército nacional que adapta el modelo de lenguaje Llama con fines defensivos.
Suscríbase al boletín TechRadar Pro para recibir las principales noticias, opiniones, características y orientación que su empresa necesita para tener éxito.
El uso de IA de código abierto con fines militares ha reavivado el debate sobre los posibles riesgos de seguridad asociados con la tecnología disponible públicamente. Meta, al igual que otras empresas de tecnología, otorgó licencias a las llamas con restricciones claras contra su uso en aplicaciones militares. Sin embargo, como ocurre con muchos proyectos de código abierto, imponer tales restricciones es prácticamente imposible. Una vez que el código fuente está disponible, se puede modificar y reutilizar, lo que permite a los gobiernos extranjeros adaptar la tecnología a sus propias necesidades. El caso de ChatBIT es un ejemplo sorprendente de este desafío, donde las metaintenciones son anuladas por aquellas con diferentes prioridades.
Esto ha llevado a nuevos llamados dentro de Estados Unidos para controles de exportación más estrictos y mayores restricciones a la capacidad de China para acceder a tecnologías de código abierto y estándares abiertos como RISC-V. Estas medidas tienen como objetivo impedir que las tecnologías estadounidenses apoyen desarrollos militares potencialmente hostiles. Los legisladores también están explorando formas de limitar las inversiones estadounidenses en los sectores de inteligencia artificial, semiconductores y computación cuántica de China para limitar el flujo de experiencia y recursos que podrían impulsar el crecimiento de la industria tecnológica de China.
A pesar de las preocupaciones que rodean a ChatBIT, algunos expertos cuestionan su eficacia dados los datos relativamente limitados utilizados en su desarrollo. Según se informa, el modelo fue entrenado en 100.000 registros de diálogos militares, un número relativamente pequeño en comparación con los enormes conjuntos de datos utilizados para entrenar modelos de lenguajes modernos en Occidente. Los analistas señalan que esto puede limitar la capacidad de ChatBIT para manejar tareas militares complejas, especialmente cuando otros grandes modelos de lenguaje se entrenan en billones de puntos de datos.
Meta también respondió a estos informes afirmando que Llama 2 13B LLM utilizado para desarrollar ChatBIT ahora es una versión desactualizada, ya que Meta ya está trabajando en Llama 4. La compañía también se ha distanciado del PLA, diciendo que cualquier uso indebido de Llama no está autorizado. . “Cualquier uso de nuestros modelos por parte del EPL no está autorizado y es contrario a nuestra política de uso aceptable”, dijo Molly Montgomery, directora de políticas públicas de Meta.
Internet es un vasto océano de conocimiento humano, pero no es ilimitado. Y los investigadores de IA casi lo han aguantado.
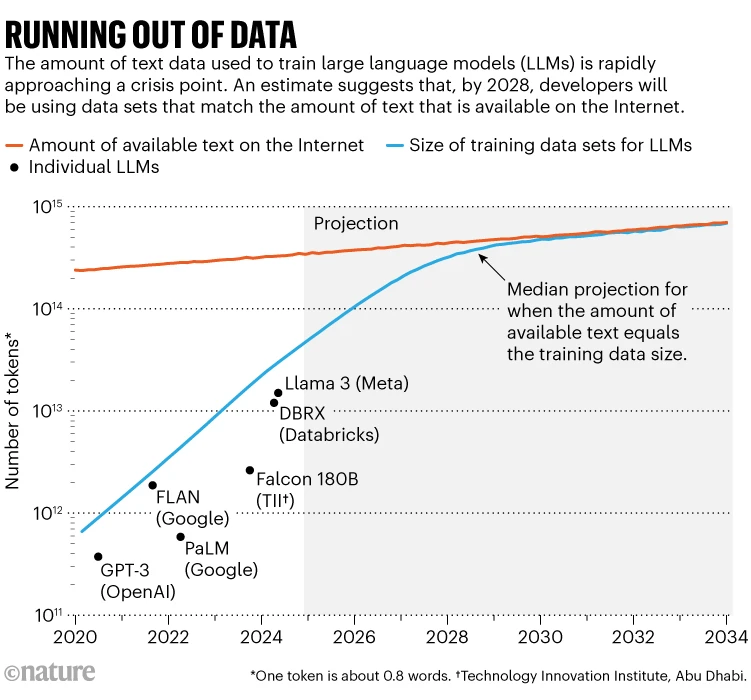
La última década de espectacular mejora en la IA ha sido impulsada en gran medida por: Haga las redes neuronales más grandes y entrénelas con más datos. Esta expansión ha demostrado ser sorprendentemente eficaz a la hora de hacer que los grandes modelos de lenguaje (LLM), como los que impulsan el chatbot ChatGPT, sean más capaces de replicar el lenguaje conversacional y desarrollar propiedades emergentes, como la inferencia. Pero algunos especialistas dicen que ahora nos estamos acercando a los límites de la expansión. Esto se debe en parte a Requisitos de energía inflados para la informática. Pero también se debe a que los desarrolladores de LLM se están quedando sin conjuntos de datos tradicionales utilizados para entrenar sus modelos.
Estudio sobresaliente1 Este año fue noticia al ponerle un número al problema: investigadores de Epoch AI, un instituto de investigación de virtualización, predicen que alrededor de 2028, el tamaño típico del conjunto de datos utilizado para entrenar un modelo de IA alcanzará el mismo tamaño total estimado. Inventario de textos públicos en línea. En otras palabras, es más probable que la IA lo haga. Nos quedamos sin datos de entrenamiento en unos cuatro años (Ver “Sin datos”). Al mismo tiempo, los propietarios de datos –como los editores de periódicos– han comenzado a tomar medidas enérgicas sobre cómo se utiliza su contenido, restringiendo aún más el acceso a los datos. Esto crea una crisis en el tamaño de los “datos comunes”, dice Shane Longbury, investigador de IA en el Instituto de Tecnología de Massachusetts en Cambridge, que dirige la Data Source Initiative, una organización de base que realiza auditorías de conjuntos de datos de IA.
El inminente cuello de botella en los datos de entrenamiento puede estar comenzando a disminuir. “Dudo mucho que esto esté sucediendo realmente”, dice Longbury.
Fuente: Referencia. 1
Aunque los especialistas dicen que existe la posibilidad de que estas limitaciones ralenticen la rápida mejora de los sistemas de IA, los desarrolladores están encontrando soluciones. “No creo que nadie esté entrando en pánico por las grandes empresas de IA”, dice Pablo Villalobos, investigador de Epoch AI con sede en Madrid y autor principal del estudio que predice un colapso de los datos en 2028. “O al menos no me envían correos electrónicos si lo hacen”.
Por ejemplo, destacadas empresas de inteligencia artificial como OpenAI y Anthropic, ambas con sede en San Francisco, California, han reconocido públicamente este problema y han sugerido que tienen planes para superarlo, incluida la generación de nuevos datos y la búsqueda de fuentes de datos no tradicionales. Un portavoz de OpenAI dijo naturaleza: “Utilizamos muchas fuentes, incluidos datos disponibles públicamente, asociaciones para datos no públicos, generación de datos sintéticos y datos de entrenadores de IA”.
Sin embargo, la crisis de datos puede revolucionar los tipos de modelos de IA generativa que la gente construye, quizás cambiando el panorama de grandes MBA multipropósito a modelos más pequeños y más especializados.
Billones de palabras
El desarrollo de LLM durante la última década ha demostrado su insaciable apetito por los datos. Aunque algunos desarrolladores no publican especificaciones para sus últimos modelos, Villalobos estima que la cantidad de “tokens” o partes de palabras utilizadas para capacitar a los LLM se ha multiplicado por 100 desde 2020, de cientos de miles de millones a decenas de billones.
En IA, ¿más grande siempre es mejor?
Esto podría ser una porción significativa de lo que hay en Internet, aunque el total general es demasiado grande para cuantificarlo: Villalobos estima que el stock total de datos textuales de Internet hoy es de aproximadamente 3.100 billones de tokens. Varios servicios utilizan rastreadores web para extraer este contenido, luego eliminan duplicados y filtran contenido no deseado (como pornografía) para producir conjuntos de datos más nítidos: un servicio popular llamado RedPajama contiene decenas de billones de palabras. Algunas empresas o académicos rastrean y limpian ellos mismos para crear conjuntos de datos personalizados para la formación de MBA. Un pequeño porcentaje de Internet es de alta calidad, como textos socialmente aceptables y editados por humanos que se pueden encontrar en libros o en la prensa.
La tasa de aumento del contenido utilizable de Internet es sorprendentemente lenta: la investigación de Villalobos estima que está creciendo a menos del 10% por año, mientras que el tamaño de los conjuntos de datos de entrenamiento de IA se duplica anualmente. La proyección de estas tendencias muestra asíntotas alrededor de 2028.
Al mismo tiempo, los proveedores de contenido incluyen cada vez más códigos de programación o mejoran sus condiciones de uso para evitar que los rastreadores web o las empresas de inteligencia artificial extraigan sus datos para capacitación. Longpre y sus colegas publicaron una preimpresión en julio de este año que muestra un fuerte aumento en la cantidad de proveedores de datos que bloquean el acceso de ciertos rastreadores a sus sitios web.2. En el contenido web de alta calidad y más utilizado en los tres principales conjuntos de datos limpiados, la cantidad de tokens bloqueados por los rastreadores aumentó de menos del 3% en 2023 al 20-33% en 2024.
Actualmente se están presentando varias demandas para tratar de obtener daños y perjuicios para los proveedores de datos utilizados en la formación de IA. En diciembre de 2023, New York Times Presentó una demanda contra OpenAI y su socio Microsoft por infracción de derechos de autor; En abril de este año, ocho periódicos propiedad de Alden Global Capital en la ciudad de Nueva York presentaron una demanda similar. El contraargumento es que a la IA se le debería permitir leer y aprender del contenido en línea de la misma manera que lo haría una persona, y que esto constituye un uso justo del material. OpenAI ha dicho públicamente el cree New York Times La demanda es “infundada”.
Si los tribunales confirman la idea de que los proveedores de contenidos merecen una compensación financiera, será más difícil para los desarrolladores e investigadores de IA obtener lo que necesitan, incluidos los académicos, que no cuentan con recursos financieros significativos. “Los académicos serán los más afectados por estos acuerdos”, dice Longbury. “Hay muchos beneficios sociales y muy democráticos que se obtienen al tener una red abierta”, añade.
encontrar datos
La escasez de datos plantea un problema potencialmente importante para la estrategia tradicional de escalar la IA. Aunque es posible aumentar la potencia de cálculo de un modelo o la cantidad de parámetros sin ampliar los datos de entrenamiento, hacerlo da como resultado una IA lenta y costosa, dice Longbury, lo cual generalmente no es deseable.
Si el objetivo es encontrar más datos, una opción podría ser recopilar datos no públicos, como mensajes de WhatsApp o transcripciones de vídeos de YouTube. Aunque aún no se ha probado la legalidad de extraer contenido de terceros de esta manera, las empresas tienen la capacidad de acceder a sus propios datos y muchas empresas de redes sociales dicen que utilizan su propio material para entrenar sus propios modelos de IA. Por ejemplo, Meta, con sede en Menlo Park, California, dice que el audio y las imágenes recopiladas por sus auriculares de realidad virtual Meta Quest se utilizan para entrenar su IA. Sin embargo, las políticas varían. Los términos de servicio de la plataforma de videoconferencia Zoom establecen que la compañía no utilizará el contenido del cliente para entrenar sistemas de inteligencia artificial, mientras que OtterAI, un servicio de transcripción, dice que utiliza audio y texto cifrados y anónimos para la capacitación.
Cómo los chips informáticos de última generación están acelerando la revolución de la inteligencia artificial
Sin embargo, por el momento, este contenido propietario probablemente contenga otros mil billones de caracteres de texto en total, estima Villalobos. Dado que gran parte de este contenido es de baja calidad o está duplicado, dice que eso es suficiente para retrasar la limitación de datos en un año y medio, incluso suponiendo que una sola IA pueda acceder a todo sin causar infracción de derechos de autor o problemas de privacidad. . “Incluso multiplicar por diez el inventario de datos sólo es suficiente para tres años de expansión”, afirma.
Otra opción podría ser centrarse en conjuntos de datos especializados, como datos astronómicos o genómicos, que están creciendo rápidamente. Fei-Fei Li, un destacado investigador de IA de la Universidad de Stanford en California, ha respaldado públicamente esta estrategia. Las preocupaciones sobre quedarse sin datos adoptan una visión demasiado estrecha de lo que constituyen datos, dada la información no explotada disponible en áreas como la atención sanitaria, el medio ambiente y la educación, dijo en una Cumbre de Tecnología de Bloomberg en mayo pasado.
Pero no está claro, dice Villalobos, qué tan disponibles o útiles son estos conjuntos de datos para capacitar a los titulares de un LLM. “Parece haber cierto grado de transferencia de aprendizaje entre muchos tipos de datos”, afirma Villalobos. “Sin embargo, no soy muy optimista acerca de este enfoque.”
Las posibilidades son más amplias si la IA generativa se entrena con otros tipos de datos, no solo con texto. Algunos modelos ya son capaces de entrenar hasta cierto punto con vídeos o imágenes sin etiquetar. Ampliar y mejorar estas capacidades puede abrir la puerta a datos más ricos.
Yann LeCun, científico senior de IA en Meta e informático de la Universidad de Nueva York, considerado uno de los fundadores de la IA moderna, destacó estas posibilidades en una presentación de febrero en la AI Meeting en Vancouver, Canadá. 1013 Los símbolos utilizados para formar a un MBA moderno parecen muchos: a una persona le llevaría 170.000 años leer tanto, estima LeCun. Pero dice que un niño de 4 años absorbió 50 veces más datos simplemente mirando objetos durante sus horas de vigilia. LeCun presentó los datos en la reunión anual de la Asociación para el Avance de la Inteligencia Artificial.