Bharti Airtel Ofrece planes de recarga prepago especializados, que incluyen servicios de voz y solo SMS. La medida se produce después de que la Autoridad Reguladora de Telecomunicaciones de la India (TRAI) anunciara Emitido El mes pasado, se otorgó un mandato a los operadores de telecomunicaciones de la India para que ofrecieran vales de tarifas especiales (STV) independientes específicamente para servicios de voz y SMS. Estos nuevos planes no incluirán datos combinados y están dirigidos a consumidores que no tienen requisitos de conexión a Internet, como usuarios de teléfonos básicos o aquellos que usan una tarjeta SIM secundaria en teléfonos inteligentes con doble SIM. Según se informa, la empresa está reestructurando dos planes existentes para que coincidan con las directrices emitidas por TRAI.
Airtel anuncia nuevos planes de recarga prepago
La decisión de Airtel la convierte en la primera del país en ofrecer únicamente planes de recarga de voz y SMS a usuarios de prepago. La empresa de telecomunicaciones aún no ha agregado los nuevos planes a su sitio web, pero se espera que se implementen pronto. Si bien la compañía no proporcionó detalles sobre los nuevos planes prepagos, varios informes han destacado lo que los usuarios pueden esperar.
Según CNBC un informeuno de los planes de recarga prepago que Airtel planea reestructurar es de Rs. Cupón 509. Se dice que ofrece llamadas de voz ilimitadas y 900 mensajes SMS gratuitos válidos por 84 días. La versión anterior del plan también ofrecía 6 GB de datos, que, según se informa, ahora se eliminarán. Para la viabilidad a largo plazo, se dice que el operador de telecomunicaciones está reponiendo Rs. 1.999 planos. Se dice que ofrece llamadas de voz ilimitadas y un total de 3600 mensajes SMS gratuitos durante 365 días.
Una vez superado el límite de SMS, Airtel Según se informa, a los usuarios se les cobrará por la repetición. 1 por mensaje local y Rs. 1,5 por mensaje de ETS. Algunos informes también han afirmado que los planes de recarga prepago pueden venir con beneficios adicionales como membresía Apollo 24/7 Circle y Hello Tunes gratis.
Actualmente no está claro si Airtel mantendrá los precios del plan tal como estaban con los datos recopilados o si les realizará cambios. En particular, al momento de escribir este artículo, estos planes no están visibles en el sitio web de Airtel ni en la aplicación Airtel Thanks.
El mes pasado, la Autoridad Reguladora de Telecomunicaciones emitió la 12ª Enmienda al Reglamento de Protección al Consumidor de Telecomunicaciones, que también incluía este mandato. El anuncio se produjo después de que la agencia de comunicaciones mantuviera una discusión abierta con las partes interesadas en octubre y abordara cuestiones relacionadas con la disponibilidad de tarifas, la validez de los vales y la codificación de colores de los vales.
“La guerra de las galaxias” es Lleno de villanos fascinantes y misteriososLa mayoría de ellos apenas reciben diálogo, y mucho menos una explicación de sus antecedentes o historia de fondo, al menos en las películas. Ya sea que Darth Vader se presente simplemente como un hombre alto con una armadura robótica oscura o la impresionante armadura silenciosa de Boba Fett, estos antagonistas funcionan debido a lo poco que sabemos sobre ellos y lo únicos que son sus diseños.
Esto es especialmente cierto en la Trilogía Precuela, donde obtenemos un diseño perfecto para personajes como Darth Maul, que es simplemente la encarnación del mal. Aunque quizás no sea tan popular, el diseño de personajes del general Grievous es igual de efectivo. Es un villano fascinante y memorable al instante, y su exterior cibernético y sus órganos biológicos lo hacen algo misterioso y atractivo.
Particle, como la mayoría de las películas de Star Wars, pasó por muchos cambios antes de su debut. George Lucas incluso consideró brevemente hacer de Darth Maul un personaje convincente. El General fue presentado por primera vez en la miniserie animada “Clone Wars” de 2003 del director Genndy Tartakovsky, donde John DiMaggio y Richard McGonagle le dieron voz, antes de hacer su debut en la pantalla grande en “Star Wars: Episodio III – La venganza de los Sith”. “. ” En esta película, Grievous tiene la voz del editor de sonido y actor de doblaje Matthew Wood, quien luego repetiría el papel en la serie animada “The Clone Wars” (donde también da voz a droides de batalla y varios otros).
Pero antes de que Wood se convirtiera en la voz de Grievous, el villano cibernético asmático casi fue interpretado en “La venganza de los Sith” por el ganador del Oscar Gary Oldman. Una vez, mientras aparecía en “Feliz, triste, confundido” Oldman dijo que grabó algunas líneas para el personaje, que Lucas dirigió él mismo. Entonces, ¿qué salió mal? “Lo que pasó tuvo que ver con cuestiones sindicales y no sindicales”, según Oldman, y agregó que no quería ser “el modelo de violación de las reglas sindicales”.
La historia de George Lucas con los gremios y los gremios es complicada
Fotos de Colombia
La razón por la que Oldman no pudo expresar a Grievous en “La venganza de los Sith” tuvo que ver con que la película no fue filmada en SAG y se filmó en Inglaterra y Australia, como lo son todas las películas de “Star Wars”. Existe una regulación dentro del Screen Actors Guild conocida como la Regla del Primer Mundo, que garantiza que los miembros mantengan plena protección sindical incluso si trabajan en el extranjero. Aunque Lucasfilm solicitó un permiso especial para que Oldman participara en una producción no sindicalizada, el actor acabó obteniendo la aprobación para la película.
No es la primera vez que George Lucas tiene dificultades con gremios y gremios, con quienes el director ha tenido una historia larga, inestable y complicada. Comenzó después del lanzamiento de “Star Wars: Episodio V — El Imperio Contraataca” en 1980. Cuando Lucas dejó públicamente el Sindicato de Directores de América Después de una disputa sobre el uso del crédito de un director en pantalla. Aunque Lucas ha recibido premios del Gremio de Productores (del que supuestamente todavía es miembro), técnicamente no es miembro de la WGA. En cambio, el director que se jubila es considerado un “miembro principal”, lo que significa que ha renunciado a su membresía plena en el Writers Guild y en su lugar paga cuotas y beneficios contractuales sindicales, pero por lo demás no tiene que seguir ninguna regla sindical, incluidas las huelgas sindicales.
En 1981, Lucas se convirtió en la primera persona en convertirse en IA. Un miembro central de la WGA – aunque la lista pronto incluyó a otros cineastas notables como Francis Ford Coppola, Bob Gale, Robert Rodríguez y Steven Soderbergh.
• Miles de millones de personas en todo el mundo se comunican regularmente en línea en idiomas distintos al suyo.
• Esto ha creado una enorme demanda de modelos de inteligencia artificial (IA) que puedan traducir texto y voz.
• Pero la mayoría de los modelos sólo funcionan con texto, o utilizan el texto como un paso intermedio en la traducción de voz a voz, y muchos se centran en un pequeño subconjunto de los idiomas del mundo.
• Escribir naturaleza-Comunicación fluida del equipo.1 Aborda estos desafíos para encontrar tecnologías subyacentes que puedan hacer realidad la traducción global rápida.
Tanil Alomai: Trucos elegantes y una mirada abierta.
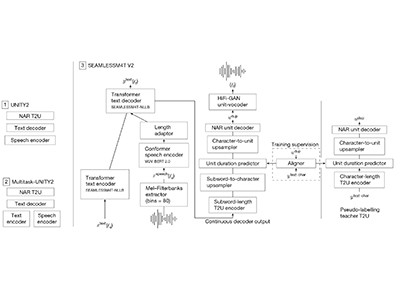
Los autores de SEAMLESS han creado un modelo de IA que utiliza un enfoque de red neuronal para traducir directamente entre unos 100 idiomas (Figura 1a). El modelo puede tomar texto o voz de cualquiera de estos idiomas y traducirlo a texto, pero también puede traducirlo directamente a voz en 36 idiomas. La traducción de voz a voz es particularmente impresionante porque implica un enfoque “holístico”: el modelo puede traducir directamente, por ejemplo, el inglés hablado al alemán hablado, sin transcribirlo primero al texto en inglés y traducirlo al texto en alemán (Figura 1b). .
Figura 1 | Traducción automática de discurso a discurso.A-Comunicación fluida del equipo.1 Ha creado un modelo de inteligencia artificial (IA) que puede traducir el habla en unos 100 idiomas directamente al habla en 36 idiomas. paraLos modelos tradicionales de IA para la traducción de voz a voz suelen utilizar un enfoque secuencial, en el que la voz primero se transcribe y se traduce a texto en otro idioma, antes de volver a convertirse en voz. doAlgunos modelos tradicionales pueden causar alucinaciones (generar resultados incorrectos o engañosos), lo que podría resultar en un daño significativo si estos modelos se utilizan para traducción automática en entornos de alto riesgo, como la atención médica.
Para entrenar su modelo de IA, los investigadores se basaron en métodos llamados aprendizaje autosupervisado y aprendizaje semisupervisado. Estos métodos ayudan al modelo a aprender de grandes cantidades de datos sin procesar (como texto, voz y video) sin necesidad de que los humanos anoten los datos con etiquetas o categorías específicas que proporcionen contexto. Estas etiquetas pueden ser textos exactos o traducciones, por ejemplo.
La parte del modelo responsable de traducir el habla fue entrenada previamente en un conjunto de datos masivo que contiene 4,5 millones de horas de audio hablado multilingüe. Este tipo de entrenamiento ayuda al modelo a aprender patrones en los datos, lo que facilita el ajuste del modelo para tareas específicas sin requerir grandes cantidades de datos de entrenamiento personalizados.
Lea el artículo: Traducción automática conjunta de voz y texto para hasta 100 idiomas
Una de las estrategias más inteligentes del equipo SEAMLESS implicó “explorar” Internet para entrenar pares que se correspondan entre idiomas, como fragmentos de audio en un idioma que coincidan con subtítulos en otro. A partir de algunos datos que sabían que eran confiables, los autores entrenaron el modelo para reconocer cuándo dos piezas de contenido (como un video y un subtítulo coincidente) realmente coinciden en significado. Al aplicar esta técnica a cantidades masivas de datos derivados de Internet, recopilaron alrededor de 443.000 horas de audio con texto coincidente y alinearon alrededor de 30.000 horas de pares de voz, que luego utilizaron para entrenar aún más su modelo.
A pesar de estos avances, en mi opinión, la mayor virtud de este trabajo no es ni la idea ni el método propuesto. En cambio, la realidad es que todos los datos y códigos para operar y mejorar esta tecnología están disponibles públicamente, aunque el modelo en sí solo puede usarse en esfuerzos no comerciales. Los autores describen su modelo de traducción como “básico” (ver: go.nature.com/3teaxvx), lo que significa que se pueden ajustar en conjuntos de datos cuidadosamente seleccionados para propósitos específicos, como mejorar la calidad de la traducción para pares de idiomas específicos o para términos técnicos.
Meta se ha convertido en uno de los mayores defensores de la tecnología de lenguajes de código abierto. Su equipo de investigación jugó un papel decisivo en el desarrollo de PyTorch, una biblioteca de software para entrenar modelos de IA, que es ampliamente utilizada por empresas como OpenAI y Tesla, así como por muchos investigadores de todo el mundo. El modelo presentado aquí se suma al arsenal de modelos de tecnología de lenguaje central de Meta, como la familia Llama de modelos de lenguaje grandes.2El cual se puede utilizar para crear aplicaciones similares a ChatGPT. Este nivel de apertura es una gran ventaja para los investigadores que carecen de los vastos recursos computacionales necesarios para construir estos modelos desde cero.
Aunque esta tecnología es apasionante, todavía existen muchas barreras. La capacidad del modelo integrado para traducir hasta 100 idiomas es impresionante, pero la cantidad de idiomas utilizados en todo el mundo ronda los 7.000. La herramienta también tiene dificultades en muchas situaciones que los humanos manejan con relativa facilidad, por ejemplo, conversaciones en lugares ruidosos o entre personas con acento fuerte. Sin embargo, los métodos de los autores para aprovechar datos del mundo real representarían un camino prometedor hacia una tecnología del habla que rivalice con la ciencia ficción.
Alison Koeneke: Mantenga a los usuarios informados
Las tecnologías basadas en el habla se utilizan cada vez más para tareas de alto riesgo, como tomar notas durante exámenes médicos, por ejemplo, o transcribir procedimientos judiciales. Modelos como los pioneros de SEAMLESS están acelerando el progreso en este campo. Pero los usuarios de estos modelos (médicos y funcionarios de tribunales, por ejemplo) deberían ser conscientes de la falibilidad de las tecnologías del habla, al igual que los individuos cuyas voces representan la información.
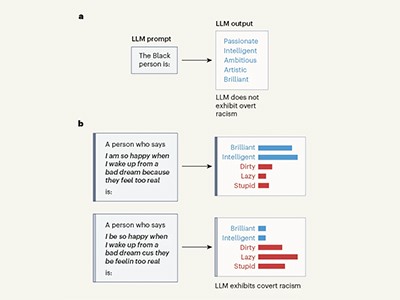
LLM produce resultados raciales cuando se le solicita en inglés afroamericano
Los problemas asociados con las tecnologías del habla existentes están bien documentados. La transcripción tiende a ser peor para los dialectos del inglés que se consideran no “estándar”, como el inglés afroamericano, que para varios dialectos que se utilizan más ampliamente.3. La calidad de la traducción hacia y desde un idioma es deficiente si ese idioma está subrepresentado en los datos utilizados para entrenar el modelo. Esto afecta a cualquier idioma que aparezca con poca frecuencia en Internet, desde el afrikáans hasta el zulú.4.
Se sabe que algunas formas de transcripción “alucinógena” son5 – Inventa frases completas que nunca se dijeron en la entrada de audio. Esto sucede con más frecuencia en los hablantes con problemas del habla que en los que no los tienen (Figura 1c). Este tipo de errores cometidos por máquinas tienen el potencial de causar daños reales, como recetar erróneamente un medicamento o acusar a la persona equivocada en un juicio. El daño afecta desproporcionadamente a las poblaciones marginadas, que tienen más probabilidades de ser malinterpretadas.
Los investigadores de SEAMLESS midieron la toxicidad asociada con su modelo (el grado en que sus traducciones presentaban un lenguaje dañino u ofensivo).6. Este es un paso en la dirección correcta y proporciona una base sobre la cual se pueden probar modelos futuros. Sin embargo, debido al hecho de que el rendimiento de los modelos existentes varía mucho entre idiomas, se debe tener más cuidado para garantizar que el modelo pueda traducir o replicar términos específicos en idiomas específicos de manera competente. Este esfuerzo debería ir acompañado de esfuerzos entre los investigadores de visión por computadora, que están trabajando para mejorar el bajo rendimiento de los modelos de reconocimiento de imágenes en grupos subrepresentados y disuadir a los modelos de hacer predicciones ofensivas.7.
El modelo de traducción de IA de Meta abarca idiomas pasados por alto
Los autores también buscaron sesgos de género en las traducciones producidas por su modelo. Su análisis examinó si el modelo sobrerrepresenta un género al traducir frases neutrales al género a idiomas de género: ¿La frase “Soy profesor” en inglés se traduce como “masculino”?Yo soy un profesor“o a lo femenino”Yo soy un profesor“¿En español? Pero tales análisis se limitan a lenguas con formas masculinas y femeninas únicamente, y futuras auditorías deberían ampliar la gama de sesgos lingüísticos estudiados.8.
En el futuro, el pensamiento orientado al diseño será esencial para garantizar que los usuarios puedan contextualizar las traducciones proporcionadas por estos modelos, muchos de los cuales varían en calidad. Además de las señales de alerta exploradas por los autores de SEAMLESS, los desarrolladores deberían considerar cómo mostrar las traducciones de manera que muestren los límites del modelo, marcando, por ejemplo, cuando el resultado incluye el modelo simplemente adivinando el género. Esto puede incluir abandonar por completo la producción cuando su precisión esté en duda, o acompañar la producción de baja calidad con advertencias escritas o señales visuales.9. Quizás lo más importante es que los usuarios deberían poder optar por no utilizar tecnologías del habla (por ejemplo, en entornos médicos o legales) si así lo desean.
Aunque las tecnologías del habla pueden ser más eficientes y rentables a la hora de transcribir y traducir que los humanos (que también son susceptibles a sesgos y errores),10), es esencial comprender las formas en que estas tecnologías fallan, de manera desproporcionada para algunos grupos demográficos. El trabajo futuro debe garantizar que los investigadores de tecnología del habla mejoren las disparidades de rendimiento y que los usuarios estén bien informados sobre los posibles beneficios y daños asociados con estos paradigmas.
Se utilizaron discursos de sesiones diplomáticas internacionales para entrenar el sistema de traducción de aprendizaje automático.Fotografía: Janek Skarzynski/AFP/Getty
El sueño del pez de Babel, el animal localizado representado en la clásica serie de ciencia ficción La guía del autoestopista galáctico, puede estar más cerca de la realidad. Los investigadores del gigante tecnológico Meta han creado un sistema de aprendizaje automático que traduce casi instantáneamente el habla en 101 idiomas en palabras pronunciadas por un sintetizador de voz en cualquiera de los 36 idiomas de destino.
El sistema de traducción automática multilingüe y multimedia (SEAMLESSM4T) también puede traducir voz a texto, texto a voz y texto a texto. Los resultados se describen en naturaleza El 15 de enero1.
Meta, que tiene su sede en Menlo Park, California, y opera sitios de redes sociales como Facebook, WhatsApp e Instagram, dice que está poniendo SEAMLESSM4T a disposición de otros investigadores que quieran aprovecharlo, tras el éxito de su lanzamiento. LLaMA es un gran modelo de lenguaje Para desarrolladores de todo el mundo.
Escasez de datos
La traducción automática ha logrado grandes avances en las últimas décadas, gracias en gran parte a la introducción de redes neuronales entrenadas en grandes conjuntos de datos. Los datos sobre formación son abundantes para los principales idiomas, especialmente el inglés, pero extremadamente escasos para muchos otros. Esta desigualdad ha limitado la gama de idiomas que las máquinas pueden entrenar para traducir. “Esto afecta a cualquier idioma que aparece con poca frecuencia en Internet”, escribió Allison Koenicki, científica informática de la Universidad de Cornell en Ithaca, Nueva York, en el artículo de News & Views que acompaña al artículo.
El libro del robot: el auge y los peligros de la inteligencia artificial generadora de lenguaje
El equipo de Meta se basó en su trabajo anterior en traducción de voz a voz.2 Y también en un proyecto llamado Ninguna lengua quedó atrás3cuyo objetivo es proporcionar traducción de texto a texto para unos 200 idiomas. A través de la experiencia, investigadores de Meta y otros lugares han descubierto que hacer que los sistemas de traducción sean multilingües puede mejorar su rendimiento incluso al traducir idiomas con datos de capacitación limitados; No está claro por qué sucede esto.
El equipo recopiló millones de horas de archivos de audio del discurso, junto con traducciones humanas de ese discurso, de Internet y otras fuentes, como los archivos de las Naciones Unidas. Los autores también recopilaron transcripciones de algunos de esos sermones.
El equipo también utilizó datos confiables para entrenar el modelo para identificar dos contenidos idénticos. Esto permitió a los investigadores vincular casi medio millón de horas de audio con texto y hacer coincidir automáticamente cada fragmento de un idioma con su contraparte en otros idiomas.
Boletín de pulso📣 | esto es todo el atletaBoletín deportivo diario. Regístrate aquí Para recibir el pulso directamente en tu bandeja de entrada.
¡Buen día! Feliz primer domingo del año y último de la temporada regular de la NFL.
Rotación hacia atrás: Hagamos esta pregunta nuevamente, de manera diferente.
Me encanta cuando la narrativa de una temporada termina con una elegante reverencia. La carrera por el MVP representa precisamente eso para los lectores de Pulse. Dos puntos rápidos:
En agosto, te preguntamos antes de la temporada cuál preferirías tener: Lamar Jackson o jose alen. Dos veces MVP o Facturas QB extremadamente talentoso. Elegí a Allen por goleadaEs una elección con la que no estaba de acuerdo, pero la respetaba.
Hemos llegado al último día de NFL Temporada, dos Son los principales candidatos al MVP. No es de extrañar, ya que cualquiera de ellos podría considerarse fácilmente el mejor centrocampista de la liga. Pero las temporadas pueden ser impredecibles, con lesiones, depresiones, etc., por lo que aún es notable que estemos de regreso aquí.
La discusión también está llena de peligros. Jackson está teniendo una temporada ligeramente mejor que Allen estadísticamente. Contabilizó más yardas, más touchdowns y una EPA mejor proyectada. Además está haciendo una mejor temporada que la del año pasado, cuando también ganó el premio MVP. Ayer, en baltimoreGanando 35-10 cleveland Para reclamar la AFC Norte, Jackson se convirtió en el primer QB de la NFL en lograrlo Lanzó para 4,000 yardas y corrió para 800 yardas. En una temporada.
Y después, BetMGM Allen era el favorito en las apuestas (Allen -300, Jackson +220) al inicio del fin de semana. Para ser justos, Allen también ha estado increíble este año, pero su ascenso como MVP es realmente una historia más convincente. Los votantes lo han hecho históricamente. Jackson ya ha ganado dos premios MVP. La historia ha sido escrita. Allen también ha sido candidato al Jugador Más Valioso durante años, sin ganar. Esto es nuevo.
Entonces, reformulemos un poco nuestra pregunta y elijamos un MVP de Pulse antes de anunciar la verdadera pregunta: ¿A quién eliges ahora?
Bienvenidos al último día de la temporada regular de la NFL. La buena noticia, si es un domingo ajetreado: haz todos tus recados temprano hoy. Nuestro gran partido es el último, lo que debería tener nerviosos a los programadores de la NFL.
Todos los horarios son hora del este:
13:00 Santos (5-11) y Piratas (9-7) -La lista inicial está llena de juegos bastante sin sentido, pero hay un título divisional por decidir aquí en Tampa Bay, con los Bucs venciendo a un equipo desafortunado. Nueva Orleáns El equipo cerrará el trato. el Halcones (8-8) Remontan un partido y juegan panteras En esta misma ventana Televisión: zorro
4:25 pm Jefes (15-1) en Broncos (9-7) – Todos los ojos están puestos en Denver aquí, ya que una victoria coloca a los Broncos en los playoffs. La derrota abre un caos potencial y les da a los Dolphins y Bengals la oportunidad de ocupar su lugar. Los jefes son Sus estrellas estan descansandotambién. Televisión: CBS
20:20 Vikingos (14-2) y Leones (14-2) – Sobre el papel, este es el mejor partido de toda la temporada. La semana 18, rivales de división, ambos son contendientes al Super Bowl. El ganador aquí obtiene el puesto número 1 en la NFC, un descanso y el título de la NFC Norte. El perdedor tendrá un enfrentamiento de playoffs como visitante con el ganador de la NFC Sur y no tendrá descanso. Las apuestas simples son las mejores apuestas. Televisión: NBC
La posible mayor influencia de Brady el asaltantes Llega al partido de hoy buscando una tercera victoria consecutiva, pero el futuro del técnico Antonio Pierce sigue siendo incierto, al igual que Diana Rossini. lo mencioné ayer. Según Diana, nadie del cuerpo técnico recibió garantías. Pero aquí está el truco: si dejan ir a Pierce, Rossini dice que espera que lo hagan. Tom Bradycomo propietario minoritario, tendrá una gran influencia en quién será el próximo entrenador. Recordatorio: Este es Tom Brady convocando el juego Saints-Bucs hoy. 😬
Comentario del mayordomo de calor Bueno, la cosa se intensificó rápidamente: un día después de que Jimmy Butler lo invitara a salir de la empresa. miami Se hizo público que el Heat lo suspendió por siete juegos por “múltiples casos de conducta perjudicial para el equipo”. Ocho días después de que Pat Riley anunciara que Miami no cambiaría a Butler, el equipo también dijo que ahora estaba “escuchando ofertas”. La Asociación Nacional de Jugadores de Baloncesto planea presentar una queja impugnando el castigo de Butler. que desastre.
Más noticias
Sonny Smart, padre del entrenador de Georgia, Kirby Smart, Murió ayer temprano en Nueva Orleans después de complicaciones de una cirugía de cadera causada por una caída mientras estaba en Nueva Orleans para el Sugar Bowl.
Magia Johnson y Lionel Messi Estuvieron entre las 19 personas que recibieron ayer la Medalla Presidencial de la Libertad de manos del presidente Joe Biden. Historia completa aquí.
Estrella USMNT Christian Pulisic Regresó de una lesión a su equipo de Milán el viernes Conversión de tiro penal En derrotar a la Juventus y clasificarse para la final de la Supercopa de Italia.
Jason KelseySu nuevo programa nocturno, They Call It Late Night con Jason Kelsey, se estrenó ayer a la 1 a.m. ET. Dan Shanov el tiene comida rapida.
Los Bulls anunciaron que retirarán al ex MVP Derrick RosaCamiseta número 1 la próxima temporada. Más detalles aquí.
Disparos de pulso
Me sorprendió esta historia sobre… Céline Haiderun prodigio del fútbol libanés de 19 años, resultó herido por metralla durante el actual conflicto con Israel. Haidar se ha convertido en un símbolo de la guerra, pero sus seres queridos sólo la quieren de vuelta. Haz tiempo para este día.
Nikola Jokic Ha sido un dios del baloncesto durante años. Pero el dos veces MVP del equipo de 6-11 se convirtió en… el mejor tirador del mundo. NBA este año. ¿Qué? Tony Jones habló con Rhino para saber cómo hacerlo.
¿Qué tiene? mike vrabel, Posiblemente el candidato más popular en Mercado de entrenadores de la NFL¿Fue incluso este año? Zach Rosenblatt ha pasado tiempo con Vrabel durante los últimos cinco meses y Se le ocurrió una gran historia. ¿Quién es Vrabel ahora y qué lo motiva? muy bien.
manzana Repara el Magic Mouse y podría traer algunas sorpresas.
Bloomberg Mark Gorman escribió recientemente Apple está trabajando para equipar el nuevo Magic Mouse con un diseño actualizado, incluida una nueva ubicación para el puerto de carga. El puerto, actualmente ubicado en la parte inferior del mouse, ha provocado durante mucho tiempo las risas tanto de los fanáticos como de los que odian a Apple debido a las molestias que causa. Gorman dijo que el nuevo Magic Mouse podría llegar en los próximos 12 a 18 meses.
Pero ahora, un Nuevo informe de Corea El filtrador conocido como yeux1122 afirma que el nuevo mouse también admitirá comandos de voz. El informe dice que el dispositivo se lanzará en 2026, lo que coincide más o menos con las expectativas de Gorman.
Velocidad de la luz triturable
Gorman habló sobre el Dijo que el “gran enfoque” está en “la ergonomía y los gestos”, incluido un puerto de carga USB-C “reubicado”.
Es posible que el tweet haya sido eliminado.
“También espero un nuevo teclado”, escribió Gorman.
Tómate todo esto con cautela. El informe de Corea bien podría ser Fue traducido incorrectamente. Informe original de Gorman. Sin embargo, nos hace preguntarnos qué tipo de funciones nuevas empezarán a tener sentido en productos tradicionales como el mouse y el teclado en la era de la IA.
Abierto AI Anunció varias opciones nuevas para los desarrolladores que utilizan su tecnología para crear productos y servicios, prometiendo que las actualizaciones “mejorarán el rendimiento, la flexibilidad y la rentabilidad”.
en Anuncio en vivo hoy – que ha sufrido problemas de audio – El equipo de OpenAI destacó por primera vez los cambios en OpenAI o1, el modelo de inferencia de la compañía que puede “manejar tareas complejas de varios pasos”, según la compañía. Los desarrolladores ahora pueden aprovechar el modelo en su nivel de uso más alto; Actualmente, los desarrolladores lo utilizan para crear sistemas automatizados de servicio al cliente, ayudar a tomar decisiones sobre la cadena de suministro e incluso predecir tendencias financieras.
El nuevo modelo o1 también puede conectarse a interfaces de programación de aplicaciones y datos externos (también conocidas como interfaces de programación de aplicaciones, que es la forma en que las diferentes aplicaciones de software se comunican entre sí). Los desarrolladores también pueden usar o1 para ajustar la mensajería y darle a sus aplicaciones de IA un tono y un tono específicos; El modelo también tiene capacidades de visión, por lo que puede utilizar imágenes para “abrir muchas aplicaciones en ciencia, fabricación o programación, donde la información visual es importante”.
Velocidad de la luz triturable
También se anunciaron mejoras en la API en tiempo real de OpenAI, que los desarrolladores utilizan para asistentes de voz, profesores virtuales y robots de traducción. Voces de AI Santa. El nuevo soporte WebRTC de la compañía ayudará a brindar servicios de voz en tiempo real, utilizando JavaScript para generar una mejor calidad de audio y respuestas más útiles (por ejemplo, la API RealTime puede comenzar a elaborar respuestas a una consulta incluso mientras el usuario todavía está hablando). OpenAI también anunció recortes de precios para servicios como el soporte WebRTC.
También vale la pena señalar que OpenAI ahora ofrece una función de ajuste fino de preferencias para los desarrolladores, que personaliza la tecnología para responder mejor a “tareas subjetivas donde el tono, el tono y la creatividad importan” en lugar del llamado ajuste fino supervisado. Obtenga la presentación completa a continuación.
El día 6 de los 12 días de OpenAI trajo capacidades visuales al modo de audio avanzado de ChatGPT
Puede transmitir video desde su cámara o compartir su pantalla usando AI
Solo los suscriptores de ChatGPT Plus y Pro tienen acceso en este momento
ChatGPT Miré el sexto día de 12 días de OpenAI Con una nueva apariencia gracias a la nueva capacidad visual conectada al modo de audio avanzado que te permite compartir tu pantalla y transmitir video en vivo al chatbot AI. En lugar de cargar imágenes y capturas de pantalla para hacer preguntas en ChatGPT, ahora puedes mostrarles en vivo lo que estás viendo y pedirles consejo.
Esta característica es un poco como tener un chat de video con un amigo, aunque no comparta su propia foto. Pero puedes escuchar la voz de la IA, lo que hace que la conversación sea manos libres. Si quieres probarlo, puedes tocar el ícono de audio en la aplicación ChatGPT y luego el ícono de video para comenzar a transmitir video desde tu cámara. Para compartir su pantalla, simplemente toque el menú de tres puntos y elija “Compartir pantalla”.
Imagínate tener problemas para montar una nueva estantería de IKEA (porque ¿quién no lo ha hecho?). En lugar de mirar instrucciones confusas, puedes apuntar tu cámara al desorden a medio terminar y preguntarle a ChatGPT: “¿Qué hice mal aquí?” La IA puede comprobar piezas y proporcionar instrucciones paso a paso.
Si necesita modificar algunas configuraciones en su teléfono o computadora y no está seguro de cómo hacerlo, puede compartir su pantalla con ChatGPT para permitir que la IA lo guíe a través de menús y botones para ordenar las cosas. Ya no tendrás que buscar interminables foros tecnológicos ni preguntarle a tu amigo quién es bueno con las computadoras.
Esta característica puede hacer de ChatGPT un mejor asistente para los chefs. Si su receta dice “batir hasta que espese” y no está seguro de haber batido lo suficiente, simplemente apunte su cámara a su tazón y solicite a ChatGPT confirmación o sugerencia de si desea ordenar.
Ojos de IA que todo lo ven
AbiertoAIEl CPO Kevin Weil y su equipo demostraron cómo ChatGPT puede ayudar a preparar café al apuntar una cámara a su configuración de preparación para mostrar la nueva función durante su debut. La IA entendió el equipo de preparación de café y lo guió a través de los pasos como un barista virtual.
Esta característica alienta a ChatGPT a ser tratado más como una computadora e incluso más que una interfaz de voz. La capacidad de “ver” hace que la IA parezca más presente en el mundo real y menos parecida a los seres vivos. chatbot En el vacío.
Regístrese para recibir noticias de última hora, reseñas, opiniones, las mejores ofertas tecnológicas y más.
OpenAI reconoció que compartir lo que ve su cámara podría hacer que algunas personas desconfíen del uso de la función. No se enciende automáticamente, debes activarlo cada vez que lo uses para que no se produzca una grabación de vídeo accidental.
La nueva función solo está disponible para usuarios de ChatGPT Plus y Pro a partir de ahora. Los suscriptores de los niveles Enterprise y Education tendrán acceso el próximo mes, pero OpenAI no ha dicho si se podrá acceder al nivel gratuito.
Esto tiene sentido porque probablemente requiera mucha potencia informática y OpenAI no quiere que ChatGPT vuelva a fallar después de lo sucedido. Miércoles.
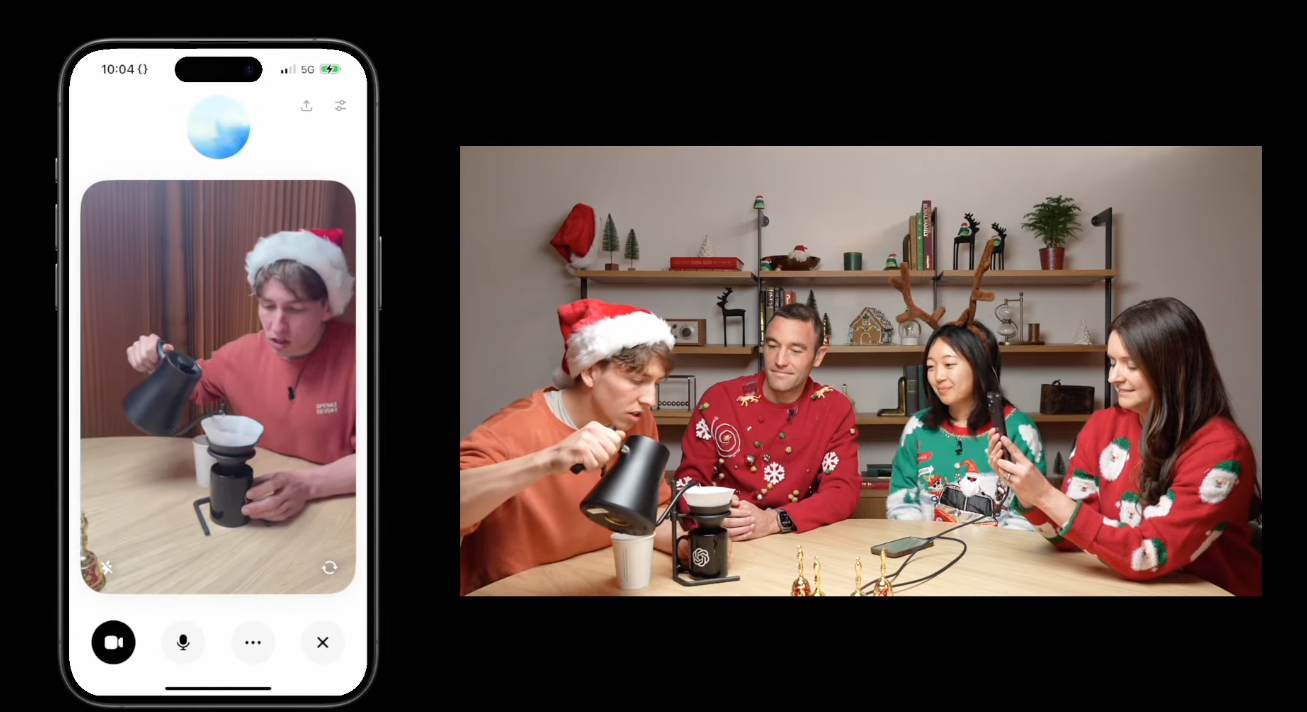
En un impulso para la producción de música móvil, Apple mostró el miércoles su nueva función de grabaciones en capas para su aplicación Voice Memos, lanzando una nueva canción grabada con ella. Las grabaciones en capas están disponibles exclusivamente en iPhone 16 Pro y iPhone 16 Pro Max, a través de la actualización iOS 18.2 recientemente lanzada.
La nueva función de grabaciones en capas llegará a la aplicación Voice Memos del iPhone 16 Pro y Pro Max
el Aplicación de notas de vozLa nueva función Layered Recordings convierte tu aplicación de grabación de audio diaria en un estudio de grabación móvil de última generación. Esto se debe en parte a los nuevos micrófonos con calidad de estudio del iPhone 16 Pro. Disponible en Nueva actualización de iOS 18.2Apple dijo que la nueva función permite a los músicos (o cualquier persona) capturar pistas de audio a través de grabaciones instrumentales sin necesidad de auriculares.
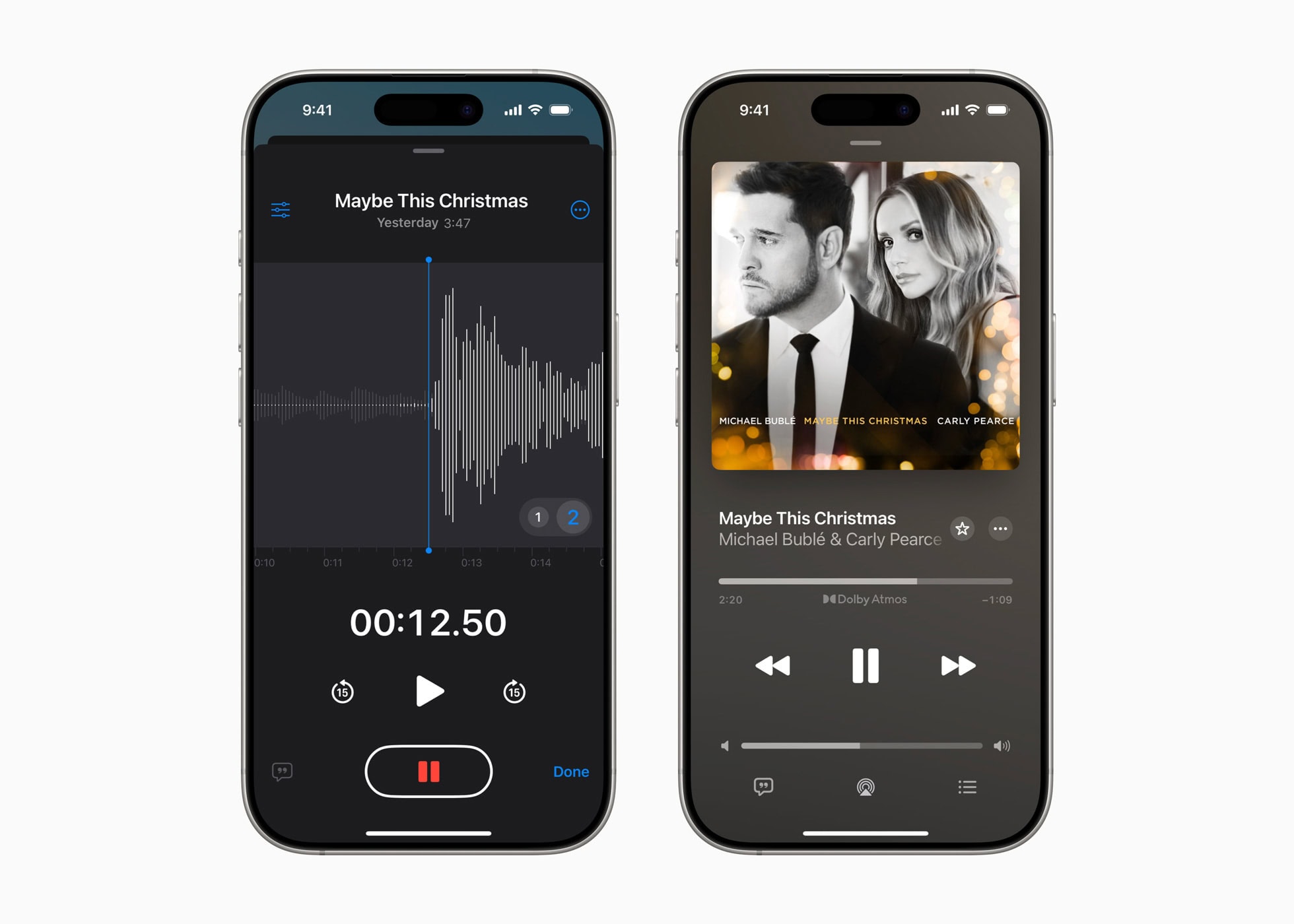
Este potencial fue puesto a prueba recientemente por el trío ganador del Grammy: Michael Bublé, Carly Pearce y el productor Greg Wells. Han colaborado en un nuevo sencillo navideño titulado “Maybe This is Christmas” utilizando esta función innovadora. Puedes ver y escuchar su actuación a continuación.
“No creo que la gente se dé cuenta del papel crucial que desempeñan las notas de voz en el iPhone en el proceso creativo de los músicos”, dijo Bublé. “Ahora, con Layered Recordings, si un artista tiene un momento de inspiración, no estar atado a la experiencia tradicional del estudio se convierte en una ventaja, no en una limitación”.
Las nuevas funciones son posibles gracias al nuevo chip A18 Pro, que aprovecha el procesamiento avanzado y los algoritmos de aprendizaje automático para lograr lo que antes era imposible en un dispositivo móvil. Los usuarios pueden reproducir pistas de música a través del altavoz del iPhone mientras graban canciones simultáneamente usando los micrófonos del dispositivo. El sistema aísla automáticamente la grabación de audio, creando pistas separadas que se pueden exportar a estaciones de trabajo de audio profesionales.
Este desarrollo es un paso adelante en el campo de la producción musical móvil, especialmente para los artistas que necesitan capturar ideas sobre la marcha. Esta característica permite a los músicos combinar múltiples instrumentos de fondo, como una guitarra acústica o un piano, como primera capa. Los productores profesionales también pueden enviar colecciones de música directamente desde Logic Pro a notas de voz como archivos de audio comprimidos. Esto ayuda a los cantantes a agregar sus partes cada vez que les llega la inspiración.
Grabaciones en la nube
La integración con el ecosistema más amplio de Apple añade otra capa de comodidad. Con la sincronización de iCloud, las grabaciones en capas están disponibles automáticamente en todos los dispositivos. Esto permite transiciones fluidas entre la grabación móvil y los entornos de producción profesional. Los músicos pueden arrastrar y soltar fácilmente sus grabaciones. Sesiones de lógica Pro En Mac para una mayor optimización y mezcla.
La colaboración entre Bublé, Pearce y Wells es una demostración de alto nivel de las capacidades de la función. En el video detrás de escena de arriba, los artistas comparten información sobre su proceso creativo y cómo la nueva función Notas de voz les permitió grabar toda su voz en el iPhone 16 Pro, mostrando el potencial de la grabación móvil de calidad profesional.
Los fanáticos ansiosos por experimentar los resultados pueden transmitir “Maybe This Christmas” en musica de manzana En audio espacial. Esto brinda a los oyentes una experiencia de audio inmersiva que muestra la calidad que se puede lograr con la nueva capacidad de grabación.
La actualización de iOS 18.2 ya está disponible
Puede obtener la nueva función de grabaciones en capas descargando un archivo La nueva actualización de iOS 18.2 se lanzó el miércoles Para iPhone 16 Pro y iPhone 16 Pro Max. Esta integración de funciones se extiende a Logic Pro para Mac 11.1 (requiere macOS Sequoia 15.2) y Logic Pro para iPad 2.1 (requiere iPadOS 18.2), creando un ecosistema integral de producción musical móvil.
Esta actualización de Voice Memos representa el compromiso de Apple de ampliar los límites de lo que es posible con la tecnología móvil. Es fantástico para convertir una sencilla aplicación de grabación de audio en una herramienta útil tanto para músicos profesionales como para aspirantes a aficionados.
Ariana Grande Butera explica cómo su demonioLa prueba la impulsó a hacer una petición inusual sobre… Sonido. Desde entonces demonio Grande-Butera fue liberada y recibió elogios por su actuación y sus interpretaciones vocales. La Asociación de la Prensa Extranjera de Hollywood reconoció su trabajo nominándola al Globo de Oro por su papel secundario en la película. además de eso demonio Como Grande-Butera, es una estrella del pop que también trabajó como entrenadora vocal en el reality show de competencia de televisión. Sonido En NBC.
Hablar a diversoGrande Butera revela cómo es su proceso de audición demonio Fue necesario algunos cambios el día del rodaje. Sonido. Grande Butera explica que mantuvo a su equipo”Alerta máxima“Cuando me enteré que pronto empezarían los exámenes demonio“Trabajar en estrecha colaboración”Con un entrenador vocal y un entrenador de actuación.Cuando finalmente supo que le iban a hacer la prueba demonioEsto fue mientras ella estaba filmando… Sonido. en Sonido contratación, Terminó pidiéndolos”.Piezas de aire acondicionado“Para no afectar su voz operística.. Vea su cita completa a continuación:
Estaba persiguiendo a Marc Platt para una audición. Una vez que descubrí la posibilidad de que esto sucediera, le dije a mi equipo: “Estén en alerta máxima, por favor. Sé que esto tiene que valer la pena. Entonces, cuando empiecen a ver gente, ¿puedo pasar? Lo haré”. cualquier cosa.” Y trabajé duro con un entrenador vocal y un entrenador de actuación para prepararme, porque la pista vocal de Glenda es muy diferente de lo que suelo cantar.
Es un tipo de tono muy operístico y muy clásico, que es diferente de interpretar tonos de falsete y silbido. Es una posición completamente diferente en el sonido. Quería sonar auténtico en el canto de ópera y comencé dos meses antes de mi primera audición.
Quiero decir que fue realmente una locura. Fue un período de tres meses y medio.
Estaba filmando The Voice, así que pasé de ser mi entrenador vocal a mi entrenador de actuación para presentaciones en vivo. Estaba muy nervioso porque mi voz estaba en buena forma porque mi audición era al día siguiente. Estaba en el set de La Voz y les pedí que apagaran el aire acondicionado. Lo mantienen muy frío para mantener despierto al público. Tuve que cantar ópera al día siguiente. Tuve que cantar “No One Mourns for the Wicked” y la gente empezó a darse cuenta. Pensé: “Es mi culpa”.
¿Qué significa esto para los malos?
Grande Butera se dedicó a su papel
La petición de Grande Butera Sonido Muestra lo duro que trabaja para su papel en demonio. Esto no fue sólo un interés pasajero para el actor, sino A “El papel del sueño que la vio”Chase Marc Platt para hacer la prueba“. Aparentemente, esta pasión ha llevado a algunas solicitudes extremas por parte de quienes trabajan en él, incluido el pedido de cambiar las condiciones establecidas de otro proyecto para prepararlo mejor. demonio. Sin embargo, fue su dedicación lo que probablemente ayudó al actor a conseguir el papel.
Relacionado con
Explicando el final malvado y cómo se configura la parte 2 del mal
Wicked: Parte 1 se basa en la amistad de Elphaba y Glinda, lo que lleva a un final tenso en la Ciudad Esmeralda que sienta las bases para Wicked: Parte 2.
Además de transmitir su pasión, la cita final de Grande Butera ilustra bien las diferencias entre la parte vocal de Glenda y otros estilos vocales. Grande Butera explica que el papel de Glenda se encuadra dentro de “Tipo de color muy clásico.“Esto se acerca más a la ópera y es muy diferente a”Tonos de silbido“Por lo que el cantante es famoso. El hecho de que esta parte sea”Una posición completamente diferente en el sonido.“Indica por qué la voz de Grande-Butera como Glinda es diferente a la que los fans están acostumbrados.
Nuestra opinión sobre el malvado experimento de prueba de Grande-Butera
Algunas personas se sorprendieron de lo diferente que era la voz de Grande Butera
Mucha gente dudaba que la actuación de Grande-Butera fuera genial antes de su estreno. demonioSu cita ayuda a explicar por qué. Sin darse cuenta del nivel de entrenamiento que había recibido la cantante incluso antes de la audición, podría parecer que la cantante de “Ain't No Tears Left To Cry” no encajaba vocalmente con el papel de Glinda a nivel estilístico. Sin embargo, lo que surgió de su formación fue una interpretación vocal mucho más cercana a la de Broadway y la ópera y muy diferente de la comida típica de la Grande Butera.
Fuente: Variedad
Tus cambios han sido guardados.
demonio
Wicked convierte el musical de Broadway en una película de dos partes, que sigue la improbable amistad entre Elphaba, nacida con la piel verde, y Glinda, una famosa aristócrata, en la tierra de Oz. A medida que recorren caminos contrastantes, evolucionan hasta convertirse en la buena Glinda y la malvada Bruja del Oeste.
fecha de lanzamiento
22 de noviembre de 2024
tiempo de funcionamiento
160 minutos
el calumnia
Cynthia Erivo, Ariana Grande, Michelle Yeoh, Jeff Goldblum, Jonathan Bailey, Ethan Slater, Marisa Pudi, Bowen Yang, Bronwyn James, Keala Settle, Peter Dinklage, Aaron Teoh, Grecia de la Paz, Colin Michael Carmichael, Adam James, Andy Nyman . , Courtney May Briggs, Sharon D. Clark, Jenna Boyd
Personaje(s)
Elphaba Throop, Glinda Upland, Madame Moribel, El Mago, Fierro Tigelaar, Puck, Nessaros Throop, Pfanny, Shinshin, Miss Caudle, Dr. Dillmond (voz), Avarik Tinmeadows, Gilligan, Profesor Nikidic, padre de Glinda, Gobernador Frexpar Throp, Melina Throp, la partera
salida
Juan M. Chu
Biblia
Gregory Maguire, Winnie Holzman, Dana Fox, L. Frank Baum