If you are interested in learning more about the performance and capabilities of the latest AI models designed and created by Google, OpenAI and X AI Elon Musk’s AI assistant. You will be pleased to know that these three advanced models have recently been put through their paces Gemini vs GPT-4 vs Grok AI to determine their capabilities across a range of tasks.
The AI models, known as Gemini Pro, GPT-4, and Grok respectively, have been scrutinized for their performance in writing, reasoning, humor, vision, coding, and music generation. For those curious about which AI might come out on top, a comprehensive Gemini vs GPT-4 vs Grok AI comparison has been made by Wes Roth to highlight their individual strengths and areas where they may fall short.
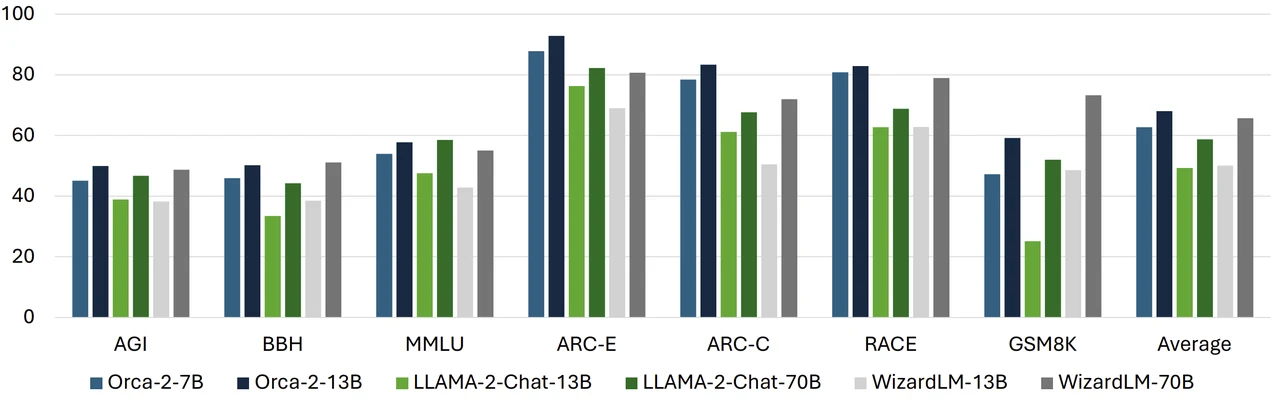
Writing performance
When it comes to writing, GPT-4 takes the lead with its ability to generate text that is not only coherent but also contextually aware. Gemini Pro is not far behind, with a strong showing in creativity and innovation in its written work. Grok, while not as focused on writing, still manages to produce respectable results. The ability to write effectively is crucial for AI, as it reflects the machine’s understanding of human language and its nuances.
Reasoning performance
Reasoning is another critical aspect of AI performance, and all three models have shown impressive abilities in this area. They can participate in complex conversations and tackle problems with a level of sophistication that might surprise many. However, each AI has its unique way of approaching abstract thinking, which highlights their different capabilities.
Gemini vs GPT-4 vs Grok

Here are some other articles you may find of interest on the subject of other AI model comparisons :
AI personality
When it comes to humor, an area that has traditionally been challenging for AI, Grok stands out. It has a nuanced understanding of human idiosyncrasies, which allows it to engage in humorous exchanges that feel surprisingly natural.
AI vision
In tasks that involve vision, such as image recognition, the models show varying levels of success. GPT-4 is particularly adept, demonstrating consistent accuracy, while Gemini Pro struggles somewhat. This highlights the significance of being able to interpret visual data, an area where GPT-4’s versatility is particularly noticeable.
Coding abilities
The AI models’ coding abilities have also been tested, with tasks that include creating browser games and writing JavaScript code. This is an area of great potential for AI in software development. Both GPT-4 and Gemini Pro exhibit strong coding skills, but GPT-4 often comes out ahead, producing code that is generally more efficient and contains fewer errors.
Musicality and composing skills
Music creation is yet another arena where these AI models have been tested. They all have the capability to compose tunes using ABC notation, but GPT-4 distinguishes itself by creating musical pieces that are both harmonious and complex, showcasing its extensive creative abilities.
The evaluation of these AI models concludes with a scoring system that ranks them based on their performance in the aforementioned areas. This system helps to clearly identify where each model excels and where there is room for improvement. If you’d like to learn more about the latest Google Gemini AI and more comparison data compared to OpenAI’s ChatGPT-4 jump over to our previous article.
What is Grok AI?
Grok is an AI model designed with a unique personality and purpose, inspired by the whimsical and insightful nature of the “Hitchhiker’s Guide to the Galaxy.” This inspiration is not just thematic but also functional, as Grok aims to provide answers to a wide array of questions, coupled with a touch of humor and a rebellious streak. This approach is a departure from traditional AI models, which often prioritize neutral and purely factual responses.
Grok’s standout feature is its real-time knowledge capability, enabled by the platform. This gives it a distinct edge, as it can access and process current information, a feature not commonly found in standard AI models. Furthermore, Grok is designed to tackle “spicy” questions, those that are usually sidestepped by conventional AI systems, potentially making it a more versatile and engaging tool for users seeking unconventional or candid responses.
Despite its innovative features, Grok is in its early beta phase, having undergone only two months of training. This indicates that while Grok shows promise, users should anticipate ongoing development and improvements. The xAI team emphasizes that user feedback will play a crucial role in shaping Grok’s evolution, highlighting their commitment to creating AI tools that are beneficial and accessible to a diverse range of users.
The journey to creating Grok-1, the engine behind Grok, involved significant advancements over a four-month period. The initial prototype, Grok-0, demonstrated impressive capabilities with fewer resources compared to models like LLaMA 2. However, it’s the subsequent development of Grok-1 that showcases substantial improvements in reasoning and coding abilities, positioning it as a state-of-the-art language model. These advancements are evident in its performance on benchmarks like the HumanEval coding task and the MMLU.
Results
Overall, GPT-4 emerges as a versatile and reliable AI across a variety of tasks. Gemini Pro is particularly noteworthy for its writing and creative contributions, although it does not perform as well in vision and music-related tasks. Grok, on the other hand, impresses with its humor and problem-solving skills, even if it doesn’t lead in every category. This analysis offers a detailed look at where each AI model stands, providing valuable insights into the complex and sophisticated world of modern artificial intelligence technology.
This Gemini vs GPT-4 vs Grok AI comparison not only serves as a benchmark for the current state of AI but also as a guide for future developments in the field. As AI continues to advance, understanding the specific capabilities and limitations of different models becomes increasingly important for both developers and users. Whether it’s for writing, reasoning, or even creating music, these AI models represent the cutting edge of technology, and their ongoing development will undoubtedly shape the future of artificial intelligence. As always we’ll keep you up to speed on all the latest developments in the world of AI.
Filed Under: Guides, Top News
Latest timeswonderful Deals
Disclosure: Some of our articles include affiliate links. If you buy something through one of these links, timeswonderful may earn an affiliate commission. Learn about our Disclosure Policy.