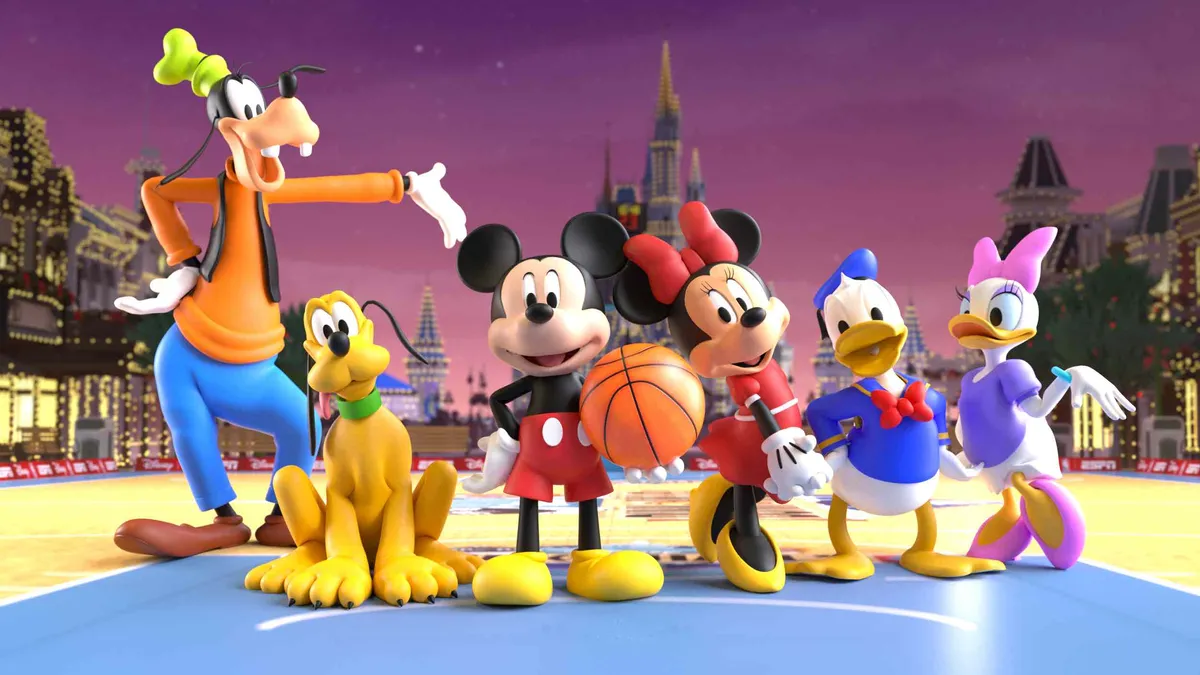Se ha detectado una nueva estafa por correo electrónico haciéndose pasar por Ledger
Los correos electrónicos afirman que la frase inicial de la billetera Ledger del usuario ha sido pirateada y solicitan confirmación.
Los usuarios que envían la frase inicial pierden todo su dinero.
Los delincuentes intentan robar criptomonedas haciéndose pasar por la empresa de billeteras de hardware Ledger y enviando correos electrónicos de phishing.
Las víctimas informaron haber recibido correos electrónicos que pretendían ser de Ledger, afirmando que su frase inicial (también conocida como frase de recuperación o semilla mnemotécnica) se había visto comprometida. Para proteger sus activos digitales, se anima a las víctimas a “verificar la seguridad” de la frase de recuperación a través de la “Herramienta de verificación segura”.
El correo electrónico viene con un botón “Verificar declaración de recuperación” que lleva a las personas a través del sitio web de AWS al campo “Libro mayor de recuperación”.[.]info”. Allí, los usuarios pueden ingresar su frase de recuperación, que luego se guarda en el servidor y se transmite a los atacantes.
Proporcionar datos correctos.
La frase de recuperación se utiliza para cargar el contenido de una billetera de criptomonedas en una nueva billetera de hardware o software. Por lo general, viene como una cadena o 12 o 24 palabras aleatorias. Todos los que tienen acceso a esta frase también tienen acceso a los fondos, por lo que es extremadamente importante que estos fondos permanezcan fuera de línea, ocultos y no se compartan con nadie.
Para asegurarse de obtener el trato real, los estafadores han agregado varias protecciones a la página de phishing. El sitio está limitado a 2048 palabras válidas que se pueden ingresar como parte de la frase de memoria inicial. Además, independientemente de lo que ingrese el usuario, recibirá una respuesta de que la declaración inicial es falsa, lo que probablemente permitirá a las víctimas duplicar sus entradas y así confirmar que proporcionaron la información correcta.
Los correos electrónicos de phishing suelen tener mala gramática y ortografía y, por lo general, pueden identificarse por una redacción torpe y poco profesional. Sin embargo, con la llegada de la IA generativa, este ya no es el caso. En este caso, la pista estaba en el encabezado del correo electrónico, porque provenía de la plataforma de email marketing SendGrid. Además, la redirección se realiza a través del enlace. Amazonas Sitio web de AWS, que también debería ser una señal de alerta.
Es imposible saber cuántas personas (si es que hubo alguna) cayeron en esta estafa, pero aquellos que cayeron en esta estafa perdieron permanentemente su dinero.
Suscríbase al boletín informativo TechRadar Pro para recibir las principales noticias, opiniones, características y orientación que su empresa necesita para tener éxito.
El castigo llega tras una violación de datos de Facebook en 2018
La Comisión Irlandesa de Protección de Datos aún no ha cobrado muchas multas
Meta ha recibido otra multa en virtud del Reglamento General de Protección de Datos (GDPR), junto con la empresa matriz de Facebook, Instagram y… WhatsApp Se enfrenta a una pérdida de 251 millones de euros (alrededor de 263 millones de dólares) después de una violación de datos en 2018 que expuso alrededor de 29 millones de cuentas de Facebook en todo el mundo, 3 millones de las cuales eran usuarios con sede en la Unión Europea.
Irlanda Comisión de Protección de Datos (DPC) Ha sido uno de los principales organismos reguladores de Europa en lo que respecta a responsabilizar a las empresas de tecnología, imponiendo enormes sanciones por violaciones del RGPD, incluida la multa más grande de la historia del RGPD. Cargo de 1.300 millones de dólares, también contra Metapara el procesamiento de datos.
La última infracción se refiere a un ataque en el que actores maliciosos utilizaron la función “Ver como”, que normalmente permite a los usuarios ver cómo ven su cuenta sus amigos y familiares, para robar tokens de acceso y tomar el control de la cuenta de los usuarios.
Millones de usuarios afectados
De los usuarios cuyos tokens fueron robados, se expusieron los números de teléfono y direcciones de correo electrónico de 15 millones, y se accedió a los nombres de usuario, género, estado civil y registros de sitios de otros 14 millones. Se atacó a un millón de afortunados usuarios y sus datos no fueron robados.
Tras la infracción, la DPC descubrió que Facebook violó el Reglamento General de Protección de Datos (GDPR) al no incluir suficiente información en la notificación de infracción y al no documentar adecuadamente los hechos del incidente. La DPC también concluyó que la empresa no garantizó que se protegieran los principios de protección de datos y que Facebook no cumplió con su “obligación como controlador” de garantizar que solo se procesen los datos personales necesarios.
El comisionado del DPC, Graham Doyle, dijo: “Esta acción de cumplimiento destaca cómo no incorporar requisitos de protección de datos durante todo el ciclo de diseño y desarrollo puede exponer a las personas a riesgos y daños muy graves, incluido el riesgo para los derechos y libertades fundamentales de las personas”.
Esto puede parecer una multa considerable, y lo es, pero la realidad de estas multas según el RGPD no es exactamente lo que parece. todavía, Sólo se cobra el 1% de estas multas de la DPCpor lo que existe la posibilidad de que esta multa también se restrinja en el proceso de apelación por tiempo indefinido.
Suscríbase al boletín informativo TechRadar Pro para recibir las principales noticias, opiniones, características y orientación que su empresa necesita para tener éxito.
ConnectOnCall Healthcare ha sufrido una violación de datos
Se accedió a los datos de más de 900.000 pacientes durante un período de tres meses.
Esto deja a los pacientes en riesgo de robo de identidad.
La empresa de software Phreesia notificó a 914.138 personas cuya información personal y de salud quedó expuesta a través de una filtración de datos en mayo de 2023 después de utilizar su software ConnectOnCall, que proporciona comunicación fuera de horario entre pacientes y médicos.
Una investigación reveló que un tercero desconocido accedió a los datos de ConnectOnCall entre el 16 de febrero y el 12 de mayo de 20203, lo que significa que las comunicaciones confidenciales entre el proveedor y el paciente se vieron comprometidas, incluidos registros médicos, información de recetas, nombres completos y números de teléfono, con un “pequeño”. De los números de la Seguridad Social también se revelaron.
El incidente suspendió los servicios de ConnectOnCall hasta que el servicio pueda evaluarse y restablecerse por completo, y Phreesia está cooperando con las autoridades para determinar el impacto potencial.
Riesgos para los pacientes
ConnectOnCall ofrecía servicios de control de identidad y crédito, pero sólo a clientes cuyos números de Seguro Social fueron revelados. Para aquellos que no estaban cubiertos, La mejor protección contra el robo de identidad Podría ser de alguna ayuda.
Aunque todavía no hay evidencia de actividad maliciosa en relación con la violación, actores desconocidos que acceden a datos de salud siempre representan un riesgo significativo.
“ConnectOnCall permanece fuera de línea y estamos trabajando diligentemente para evaluar el impacto potencial y restaurar el servicio”, dice el comunicado de la compañía.
“Aunque ConnectOnCall no tiene conocimiento de ningún uso indebido de información personal o daño a los pacientes como resultado de este incidente, se alienta a las personas potencialmente afectadas a permanecer alerta e informar cualquier sospecha de robo de identidad o fraude a su plan de salud, compañía de seguros o institución financiera. ” “
Suscríbase al boletín informativo TechRadar Pro para recibir las principales noticias, opiniones, características y orientación que su empresa necesita para tener éxito.
La noticia es la última de una serie de… Violaciones de la atención sanitaria en 2024Los ciberdelincuentes se dirigen a la industria gracias a la naturaleza sensible de los datos almacenados y la naturaleza crítica del servicio prestado.
El Centro de Ciencias de la Salud de la Universidad Tecnológica de Texas y El Paso confirmó que había sido objeto de un ciberataque
En el ataque se filtraron datos sobre 1,4 millones de personas
Un actor de amenazas llamado Interlock se atribuyó la responsabilidad del ataque.
Otro hospital importante de EE. UU. sufrió recientemente un ciberataque y, como resultado, perdió datos confidenciales de más de un millón de pacientes.
En un anuncio publicado en su sitio web, el Centro de Ciencias de la Salud de la Universidad Tecnológica de Texas y los Centros de Ciencias de la Salud (HSC) de El Paso de la Universidad Tecnológica de Texas confirmaron que habían experimentado una “interrupción temporal en algunos sistemas y aplicaciones informáticas”.
La investigación posterior confirmó que el trastorno era el resultado de ransomware El ataque en el que “ciertos archivos y carpetas” fueron eliminados de la red de HSC. El ataque supuestamente ocurrió el 17 de septiembre y fue descubierto más de una semana después, el 29 de septiembre.
Otro hospital fue atacado
El aviso no decía cuántas personas se vieron afectadas ni quiénes eran los atacantes, pero en una presentación separada ante la Oficina de Derechos Civiles del Departamento de Salud y Servicios Humanos de Estados Unidos, decía que la cifra era 1.465.000.
Las HSC concluyeron que los estafadores robaron datos confidenciales como nombres de personas, fecha de nacimiento, dirección, número de Seguro Social, número de licencia de conducir, número de identificación emitido por el gobierno, información de cuentas financieras, información de seguros médicos e información médica, incluidos números de registros médicos. , datos de facturación/reclamos e información de diagnóstico y tratamiento.
El actor de amenaza detrás de este ataque se llama Interlock y parece ser una operación de ransomware relativamente nueva, dirigida a organizaciones de alto perfil y exigiendo rescates de cientos de miles de dólares. El grupo agregó recientemente datos de HSC a su sitio de filtración, mostrando 2,1 millones de archivos, con un total de 2,6 terabytes.
Para combatir el ataque, los HSC están revisando actualmente las políticas y procedimientos de seguridad actuales y están implementando salvaguardas adicionales para mejorar la protección y el monitoreo del sistema, según el anuncio. Como medida de precaución, se ofrecen servicios gratuitos de monitoreo de crédito a las personas afectadas, agregaron los HSC.
Suscríbase al boletín informativo TechRadar Pro para recibir las principales noticias, opiniones, características y orientación que su empresa necesita para tener éxito.
Los expertos advierten que los ataques de ransomware a menudo apuntan directamente a los datos de respaldo
Los principios de Zero Trust son clave para la protección de datos
El 59% de las organizaciones sufrieron ataques de ransomware en 2023
ransomware Los ataques se están convirtiendo cada vez más en una preocupación importante para las empresas de todo el mundo y se dirigen a organizaciones de todos los tamaños e industrias.
Una investigación reciente de Object First ha puesto de relieve vulnerabilidades clave y la creciente importancia de las tecnologías de copia de seguridad modernas en la lucha contra las amenazas de ransomware.
La encuesta reveló que muchas empresas todavía utilizan tecnologías obsoletas que hacen que sus datos de respaldo sean vulnerables a los ataques, lo que indica que aún no están adecuadamente preparadas para protegerse de los ataques de ransomware modernos.
Estado de seguridad de la copia de seguridad
Los datos de respaldo se han convertido en un objetivo principal para los ciberdelincuentes, por lo que las organizaciones deben repensar sus prácticas de seguridad de respaldo para adoptar soluciones más resilientes y resistentes al ransomware.
El informe reveló que, si bien más de un tercio de los encuestados (34%) citó los sistemas de respaldo obsoletos como una vulnerabilidad importante, lo que los convierte en objetivos más fáciles para los atacantes de ransomware, el 31% citó la falta de datos de respaldo. Cifradolo que impide que los datos confidenciales se almacenen y transmitan de forma segura.
Además, el 28% de los encuestados consideró que las copias de seguridad de datos fallidas eran otra vulnerabilidad importante. Estas fallas dejan a las organizaciones incapaces de recuperar sus sistemas después de un ataque, lo que a menudo resulta en largos tiempos de inactividad y recuperaciones costosas.
Aún más preocupante es el descubrimiento de que los ataques de ransomware se dirigen cada vez más directamente a los datos de respaldo. Normalmente, los refuerzos son la última línea de defensa en caso de un ataque. Sin embargo, ahora que los atacantes se centran en comprometer estos datos, simplemente tener copias de seguridad ya no es suficiente. Este cambio ha llevado a una creciente necesidad de sistemas de respaldo de almacenamiento inmutables diseñados para garantizar que el ransomware no pueda alterar ni eliminar los datos una vez almacenados.
Suscríbase al boletín informativo TechRadar Pro para recibir las principales noticias, opiniones, características y orientación que su empresa necesita para tener éxito.
El 93 % de los encuestados estuvo de acuerdo en que el almacenamiento inmutable es esencial para protegerse contra ataques de ransomware, mientras que el 84 % de los trabajadores de TI confirmaron que necesitan una mejor seguridad de respaldo para cumplir con el cumplimiento normativo. Esta necesidad de mejorar la seguridad se demuestra aún más por el hecho de que el 97% de los encuestados planea invertir en soluciones de almacenamiento inmutables como parte de su estrategia de ciberseguridad.
El almacenamiento inmutable se basa en los principios de Zero Trust, un modelo de seguridad que asume que ningún usuario o sistema es inherentemente confiable. Este enfoque se centra en validar constantemente cada solicitud de acceso y limitar los permisos para reducir el riesgo de acceso no autorizado.
La encuesta Object First encontró que el 93% de los profesionales de TI creen que alinear sus sistemas de respaldo con los principios de Confianza Cero es clave para proteger sus datos del ransomware. La arquitectura Zero Trust garantiza que incluso si los ciberdelincuentes obtienen acceso al sistema, su capacidad para manipular o eliminar datos importantes será limitada.
Si bien la necesidad de mejorar la seguridad es clara, la encuesta también reveló que la gestión de sistemas de almacenamiento de respaldo sigue siendo un desafío para muchas organizaciones. Casi el 41% de los profesionales de TI dijeron que carecen de las habilidades para administrar soluciones de respaldo complejas y el 69% informó que las restricciones presupuestarias les impiden contratar expertos en seguridad adicionales.
“Nuestra investigación muestra que casi la mitad de las organizaciones han sufrido ataques dirigidos a sus datos de respaldo, lo que destaca la importancia de adoptar soluciones de almacenamiento de respaldo resistentes al ransomware”, dijo Andrew Whitman, CMO de Object First.
macOS se enfrenta a una amenaza emergente de ransomware, NotLockBit
El malware NotLockBit muestra capacidades de bloqueo de archivos
Las protecciones integradas de Apple están experimentando problemas debido a sofisticadas amenazas de ransomware
Durante años, ransomware Los ataques se dirigieron principalmente a los sistemas operativos Windows y Linux, pero los ciberdelincuentes han comenzado a centrar su atención en los usuarios de macOS, afirman los expertos.
El reciente descubrimiento de macOS.NotLockBit indica un cambio en el panorama, como se identificó recientemente malwareque lleva el nombre de la infame variante LockBit, podría marcar el comienzo de campañas de ransomware más serias contra usuarios de Mac.
Fue descubierto por investigadores de Trend Micro y luego analizado por Laboratorios centinelamacOS.NotLockBit muestra capacidades confiables de bloqueo de archivos y filtración de datos, lo que representa un peligro potencial para los usuarios de macOS.
Amenaza macOS.NotLockBit
El ransomware dirigido a Mac tiende a carecer de las herramientas necesarias para bloquear archivos o filtrar datos. La percepción general ha sido que macOS está mejor protegido contra este tipo de amenazas, en parte porque… manzanaFunciones de seguridad integradas, como protección de Transparencia, Consentimiento y Control (TCC). Sin embargo, la aparición de macOS.NotLockBit indica que los piratas informáticos están desarrollando activamente métodos más sofisticados para atacar los dispositivos Apple.
macOS.NotLockBit funciona de manera similar a otros ransomware, pero apunta específicamente a sistemas macOS. El malware simplemente funciona IntelMac basadas en Apple Silicon o Mac con emulación Rosetta instalada, lo que les permite ejecutar archivos binarios x86_64 en procesadores Apple más nuevos.
Tras su ejecución, el ransomware recopila información del sistema, incluido el nombre del producto, la versión y la arquitectura. También recopila datos sobre cuánto tiempo ha estado activo el sistema desde su último reinicio. Antes de bloquear los archivos de un usuario, macOS.NotLockBit intenta extraer datos a un servidor remoto usando… Amazonas Almacenamiento de servicios web (AWS) S3. El malware utiliza una clave pública asimétrica. CifradoLo que significa que el descifrado sin la clave privada del atacante es casi imposible.
El malware coloca el archivo README.txt en directorios que contienen archivos cifrados. Los archivos cifrados están marcados con una extensión “.abcd” y el archivo README indica a las víctimas cómo recuperar sus archivos, generalmente pagando un rescate. Además, en versiones posteriores del malware, macOS.NotLockBit muestra un fondo de escritorio con el tema LockBit 2.0, con la marca elegida por el grupo LockBit Ransomware.
Suscríbase al boletín TechRadar Pro para recibir las principales noticias, opiniones, características y orientación que su empresa necesita para tener éxito.
Afortunadamente, la protección TCC de Apple sigue siendo un dolor de cabeza para macOS.NotLockBit. Estas salvaguardas requieren el consentimiento del usuario antes de otorgar acceso a evidencia confidencial o permitir el control de procesos como eventos del sistema. Si bien esto crea un obstáculo para la funcionalidad completa del ransomware, eludir la protección TCC no es insuperable, y los expertos en seguridad esperan que futuras iteraciones del malware puedan desarrollar formas de eludir estas alertas.
Los investigadores de SentinelLabs y Trend Micro aún no han identificado un método de distribución específico y no se conocen víctimas en este momento. Sin embargo, la rápida evolución del malware, demostrada por el tamaño y la complejidad cada vez mayores de cada nueva muestra, indica que los atacantes están trabajando activamente para mejorar sus capacidades.
SentinelLabs ha identificado varias versiones del malware, lo que indica que macOS.NotLockBit todavía está en desarrollo activo. Las primeras muestras parecían más ligeras en funcionalidad, centrándose únicamente en el cifrado. Las versiones posteriores agregaron capacidades de extracción de datos y comenzaron a utilizar el almacenamiento en la nube AWS S3 para filtrar archivos robados. Los atacantes codificaron las credenciales de AWS en el malware para crear nuevos repositorios para almacenar los datos de las víctimas, aunque estas cuentas han sido desactivadas desde entonces.
En una de sus versiones más recientes, macOS.NotLockBit requiere macOS Sonoma, lo que sugiere que los desarrolladores de malware están apuntando a algunas de las últimas versiones de macOS. También mostró intentos de ofuscar el código, lo que sugiere que los atacantes están probando diferentes técnicas para evitar la detección. antivirus programación.
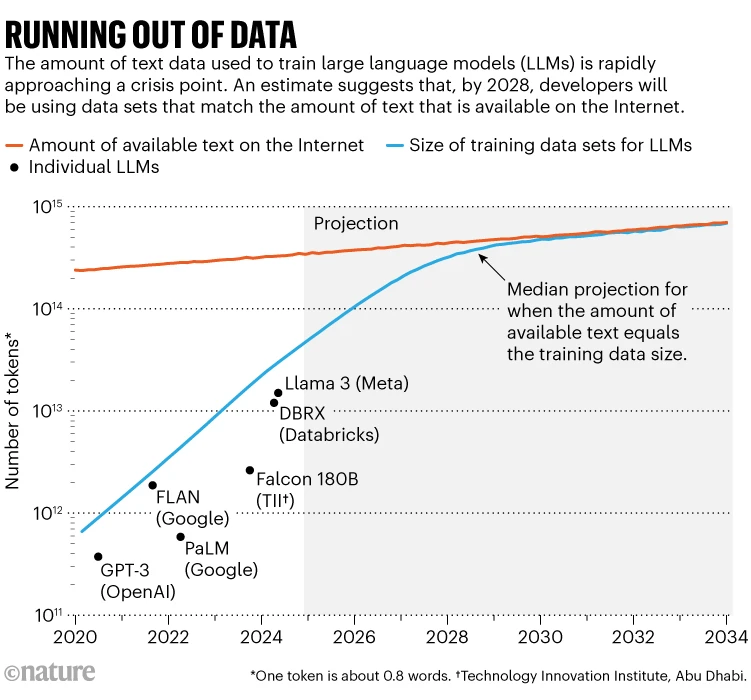
Internet es un vasto océano de conocimiento humano, pero no es ilimitado. Y los investigadores de IA casi lo han aguantado.
La última década de espectacular mejora en la IA ha sido impulsada en gran medida por: Haga las redes neuronales más grandes y entrénelas con más datos. Esta expansión ha demostrado ser sorprendentemente eficaz a la hora de hacer que los grandes modelos de lenguaje (LLM), como los que impulsan el chatbot ChatGPT, sean más capaces de replicar el lenguaje conversacional y desarrollar propiedades emergentes, como la inferencia. Pero algunos especialistas dicen que ahora nos estamos acercando a los límites de la expansión. Esto se debe en parte a Requisitos de energía inflados para la informática. Pero también se debe a que los desarrolladores de LLM se están quedando sin conjuntos de datos tradicionales utilizados para entrenar sus modelos.
Estudio sobresaliente1 Este año fue noticia al ponerle un número al problema: investigadores de Epoch AI, un instituto de investigación de virtualización, predicen que alrededor de 2028, el tamaño típico del conjunto de datos utilizado para entrenar un modelo de IA alcanzará el mismo tamaño total estimado. Inventario de textos públicos en línea. En otras palabras, es más probable que la IA lo haga. Nos quedamos sin datos de entrenamiento en unos cuatro años (Ver “Sin datos”). Al mismo tiempo, los propietarios de datos –como los editores de periódicos– han comenzado a tomar medidas enérgicas sobre cómo se utiliza su contenido, restringiendo aún más el acceso a los datos. Esto crea una crisis en el tamaño de los “datos comunes”, dice Shane Longbury, investigador de IA en el Instituto de Tecnología de Massachusetts en Cambridge, que dirige la Data Source Initiative, una organización de base que realiza auditorías de conjuntos de datos de IA.
El inminente cuello de botella en los datos de entrenamiento puede estar comenzando a disminuir. “Dudo mucho que esto esté sucediendo realmente”, dice Longbury.
Fuente: Referencia. 1
Aunque los especialistas dicen que existe la posibilidad de que estas limitaciones ralenticen la rápida mejora de los sistemas de IA, los desarrolladores están encontrando soluciones. “No creo que nadie esté entrando en pánico por las grandes empresas de IA”, dice Pablo Villalobos, investigador de Epoch AI con sede en Madrid y autor principal del estudio que predice un colapso de los datos en 2028. “O al menos no me envían correos electrónicos si lo hacen”.
Por ejemplo, destacadas empresas de inteligencia artificial como OpenAI y Anthropic, ambas con sede en San Francisco, California, han reconocido públicamente este problema y han sugerido que tienen planes para superarlo, incluida la generación de nuevos datos y la búsqueda de fuentes de datos no tradicionales. Un portavoz de OpenAI dijo naturaleza: “Utilizamos muchas fuentes, incluidos datos disponibles públicamente, asociaciones para datos no públicos, generación de datos sintéticos y datos de entrenadores de IA”.
Sin embargo, la crisis de datos puede revolucionar los tipos de modelos de IA generativa que la gente construye, quizás cambiando el panorama de grandes MBA multipropósito a modelos más pequeños y más especializados.
Billones de palabras
El desarrollo de LLM durante la última década ha demostrado su insaciable apetito por los datos. Aunque algunos desarrolladores no publican especificaciones para sus últimos modelos, Villalobos estima que la cantidad de “tokens” o partes de palabras utilizadas para capacitar a los LLM se ha multiplicado por 100 desde 2020, de cientos de miles de millones a decenas de billones.
En IA, ¿más grande siempre es mejor?
Esto podría ser una porción significativa de lo que hay en Internet, aunque el total general es demasiado grande para cuantificarlo: Villalobos estima que el stock total de datos textuales de Internet hoy es de aproximadamente 3.100 billones de tokens. Varios servicios utilizan rastreadores web para extraer este contenido, luego eliminan duplicados y filtran contenido no deseado (como pornografía) para producir conjuntos de datos más nítidos: un servicio popular llamado RedPajama contiene decenas de billones de palabras. Algunas empresas o académicos rastrean y limpian ellos mismos para crear conjuntos de datos personalizados para la formación de MBA. Un pequeño porcentaje de Internet es de alta calidad, como textos socialmente aceptables y editados por humanos que se pueden encontrar en libros o en la prensa.
La tasa de aumento del contenido utilizable de Internet es sorprendentemente lenta: la investigación de Villalobos estima que está creciendo a menos del 10% por año, mientras que el tamaño de los conjuntos de datos de entrenamiento de IA se duplica anualmente. La proyección de estas tendencias muestra asíntotas alrededor de 2028.
Al mismo tiempo, los proveedores de contenido incluyen cada vez más códigos de programación o mejoran sus condiciones de uso para evitar que los rastreadores web o las empresas de inteligencia artificial extraigan sus datos para capacitación. Longpre y sus colegas publicaron una preimpresión en julio de este año que muestra un fuerte aumento en la cantidad de proveedores de datos que bloquean el acceso de ciertos rastreadores a sus sitios web.2. En el contenido web de alta calidad y más utilizado en los tres principales conjuntos de datos limpiados, la cantidad de tokens bloqueados por los rastreadores aumentó de menos del 3% en 2023 al 20-33% en 2024.
Actualmente se están presentando varias demandas para tratar de obtener daños y perjuicios para los proveedores de datos utilizados en la formación de IA. En diciembre de 2023, New York Times Presentó una demanda contra OpenAI y su socio Microsoft por infracción de derechos de autor; En abril de este año, ocho periódicos propiedad de Alden Global Capital en la ciudad de Nueva York presentaron una demanda similar. El contraargumento es que a la IA se le debería permitir leer y aprender del contenido en línea de la misma manera que lo haría una persona, y que esto constituye un uso justo del material. OpenAI ha dicho públicamente el cree New York Times La demanda es “infundada”.
Si los tribunales confirman la idea de que los proveedores de contenidos merecen una compensación financiera, será más difícil para los desarrolladores e investigadores de IA obtener lo que necesitan, incluidos los académicos, que no cuentan con recursos financieros significativos. “Los académicos serán los más afectados por estos acuerdos”, dice Longbury. “Hay muchos beneficios sociales y muy democráticos que se obtienen al tener una red abierta”, añade.
encontrar datos
La escasez de datos plantea un problema potencialmente importante para la estrategia tradicional de escalar la IA. Aunque es posible aumentar la potencia de cálculo de un modelo o la cantidad de parámetros sin ampliar los datos de entrenamiento, hacerlo da como resultado una IA lenta y costosa, dice Longbury, lo cual generalmente no es deseable.
Si el objetivo es encontrar más datos, una opción podría ser recopilar datos no públicos, como mensajes de WhatsApp o transcripciones de vídeos de YouTube. Aunque aún no se ha probado la legalidad de extraer contenido de terceros de esta manera, las empresas tienen la capacidad de acceder a sus propios datos y muchas empresas de redes sociales dicen que utilizan su propio material para entrenar sus propios modelos de IA. Por ejemplo, Meta, con sede en Menlo Park, California, dice que el audio y las imágenes recopiladas por sus auriculares de realidad virtual Meta Quest se utilizan para entrenar su IA. Sin embargo, las políticas varían. Los términos de servicio de la plataforma de videoconferencia Zoom establecen que la compañía no utilizará el contenido del cliente para entrenar sistemas de inteligencia artificial, mientras que OtterAI, un servicio de transcripción, dice que utiliza audio y texto cifrados y anónimos para la capacitación.
Cómo los chips informáticos de última generación están acelerando la revolución de la inteligencia artificial
Sin embargo, por el momento, este contenido propietario probablemente contenga otros mil billones de caracteres de texto en total, estima Villalobos. Dado que gran parte de este contenido es de baja calidad o está duplicado, dice que eso es suficiente para retrasar la limitación de datos en un año y medio, incluso suponiendo que una sola IA pueda acceder a todo sin causar infracción de derechos de autor o problemas de privacidad. . “Incluso multiplicar por diez el inventario de datos sólo es suficiente para tres años de expansión”, afirma.
Otra opción podría ser centrarse en conjuntos de datos especializados, como datos astronómicos o genómicos, que están creciendo rápidamente. Fei-Fei Li, un destacado investigador de IA de la Universidad de Stanford en California, ha respaldado públicamente esta estrategia. Las preocupaciones sobre quedarse sin datos adoptan una visión demasiado estrecha de lo que constituyen datos, dada la información no explotada disponible en áreas como la atención sanitaria, el medio ambiente y la educación, dijo en una Cumbre de Tecnología de Bloomberg en mayo pasado.
Pero no está claro, dice Villalobos, qué tan disponibles o útiles son estos conjuntos de datos para capacitar a los titulares de un LLM. “Parece haber cierto grado de transferencia de aprendizaje entre muchos tipos de datos”, afirma Villalobos. “Sin embargo, no soy muy optimista acerca de este enfoque.”
Las posibilidades son más amplias si la IA generativa se entrena con otros tipos de datos, no solo con texto. Algunos modelos ya son capaces de entrenar hasta cierto punto con vídeos o imágenes sin etiquetar. Ampliar y mejorar estas capacidades puede abrir la puerta a datos más ricos.
Yann LeCun, científico senior de IA en Meta e informático de la Universidad de Nueva York, considerado uno de los fundadores de la IA moderna, destacó estas posibilidades en una presentación de febrero en la AI Meeting en Vancouver, Canadá. 1013 Los símbolos utilizados para formar a un MBA moderno parecen muchos: a una persona le llevaría 170.000 años leer tanto, estima LeCun. Pero dice que un niño de 4 años absorbió 50 veces más datos simplemente mirando objetos durante sus horas de vigilia. LeCun presentó los datos en la reunión anual de la Asociación para el Avance de la Inteligencia Artificial.
Si eres fanático Los Simpson O fútbol, es seguro decir que el Monday Night Football de esta semana fue un juego para los libros, y no, no me refiero a la transmisión tradicional. En cambio, fue sonyBeyond Sports, NFL, ESPN y Disney Plus se unen para crear un equipo alternativo épico que fue divertido para toda la familia.
Ah, y se necesitan muchos conocimientos tecnológicos, y probablemente algo de pastel, para cruzar la línea. Para ilustrar cómo y para qué se eliminó la transmisión alternativa en tiempo real del juego entre los Cincinnati Bengals y los Dallas Cowboys. Los SimpsonTechRadar habló con Sander Schouten, director general y cofundador de Beyond Sports.
Y es una historia de suma de partes en la que Sony Beyond Sports creó esta transmisión en tiempo real, esencialmente absorbiendo la transmisión en vivo y diferentes puntos de datos y reanimándolos en estos personajes 3D, incluso a veces cuando Lisa está corriendo en el campo. – es una historia de gran avance tecnológico.
Como describió Schouten, la transmisión de video del juego es procesada ópticamente por Sony Hawkeye, así como por Next Gen Stats (NGS) de la NFL, una colección de datos individuales a nivel de jugador gracias a un sensor integrado en el uniforme.
Él dijo: Entonces la hierba es verde. Todo lo que está encima del césped no es verde, por lo que podemos rastrear tus píxeles. Esta es solo una posición en el campo, por lo que los datos de NGS ayudan a que la transmisión sea más “natural”. Es cómo se juega realmente el juego y cómo se mueve el jugador, pero también cambia rápidamente para tener en cuenta cómo alguien podría correr el balón por el campo.
También necesita ambos flujos de datos (transmisión en vivo y estadísticas de sensores) para calcular la oclusión. Al fin y al cabo, el fútbol es un deporte de contacto. Desde el inicio de Sony Beyond Sports hasta su estado actual, ha habido un tesoro de más datos y la inclusión de sensores en el reproductor para una combinación más convincente.
Schouten compartió que rastrean “al menos 29 puntos estructurales por persona, además del balón y la portería en el campo. Esto ya es mucho y lo hacemos unas 50 veces por segundo, por lo que hay muchos datos.
Regístrese para recibir noticias de última hora, reseñas, opiniones, las mejores ofertas tecnológicas y más.
Otro gran cambio es este. Fanday de fútbol de los Simpson Y colaboraciones anteriores con Disney y Pixar para historia del juguete– El tema de la transmisión fue que los jugadores estaban en el campo; Schouten incluso explicó que tuvieron que usar estadísticas de sensores para ayudar a dar forma a los movimientos del jugador en Lisa. Incluso hubo un momento en el que Bart Simpson trabajó con Ralph Wiggum, el hijo del presidente Wiggum, para anotar un touchdown con Lisa Simpson del otro lado. Una vez más, todo en tiempo real, procesado a partir de jugadores reales de los Bengals o los Cowboys, se convirtió en animación.
Antes del día del partido, que fue el 9 de diciembre de 2024, Schouten y el equipo Beyond Sports de Sony trabajaron con animadores para Los Simpson Crear el estadio Springfield Atoms y pregrabar algunos elementos del juego, incluso con el abuelo Simpson entre la multitud y seleccionando elementos de la cámara del cielo. Es este aspecto de la narración el que ha sido un punto conflictivo para Schouten. “Si realmente lo piensas, creo que esto será algo vinculante para las generaciones”, dijo. “De esto se trata el deporte, de unir a las personas, y esta es una manera de unir a las generaciones a lo largo del tiempo. de nuevo.
(Crédito de la imagen: Disney)
Ahora, aunque Beyond Sports de Sony se ha asociado anteriormente con la NFL, la marca también tendrá que lidiar con un problema. NBA con Dunk The Holes' El primer juego animado en tiempo real de la liga se llevará a cabo en Main Street USA en Disney World con la presencia de Mickey y Minnie para el juego entre los San Antonio Spurs y los New York Knicks. Esto se transmitirá en Disney Plus y ESPN Plus el día de Navidad, 25 de diciembre de 2024.
Schouten dijo que, en cuanto al baloncesto, “espera menos volatilidad en el flujo de datos”, como ocurre en el caso de los partidos bajo techo, con menos gente en la cancha en ese momento. Considerando el elenco de notables, dijo que es un buen desafío.
Como Sony Beyond Sports espera crear más juegos en el futuro, ya sea NFL o NBA, el objetivo es una mayor interactividad, con códigos QR para minijuegos en pantalla o incluso colaboraciones con otras marcas de Sony. Si bien Schouten se apresuró a señalar que no había nada firmado ni sellado, dijo: “Somos parte de Sony, y Sony es propietaria de la consola de juegos llamada PlayStation, y puedo ver que suceden cosas allí. Ya tienes una consola en las manos, y ese es un paso allí.” “Hemos pasado de uno a muchos a muchos a muchos”.
La creatividad parece no tener límites en Beyond Sports, y no me importaría hacerme cargo del partido algún día, ya sea Mickey- simpsons-o Temática de Toy Story. Quién sabe, tal vez la próxima temporada de la NFL tengamos todos los domingos como día de donación de fútbol.
CISA exige a las organizaciones de sectores críticos actualizar su seguridad
Se aplicará MFA, gestión de vulnerabilidades y cifrado de datos.
Estos cambios ayudarán a mitigar el potencial de robo de datos por parte del gobierno y actores patrocinados por el estado.
La Agencia de Seguridad de Infraestructura y Ciberseguridad de EE. UU. (CISA) ha revelado un conjunto de Requisitos de seguridad propuestos Su objetivo es reducir los riesgos que plantea el acceso no autorizado a datos estadounidenses.
La medida se debe a preocupaciones sobre las vulnerabilidades expuestas por recientes ciberataques, campañas de piratería patrocinadas por estados y el uso indebido de datos personales por parte de naciones hostiles.
La propuesta es consistente con la Orden Ejecutiva 14117, firmada por el presidente Biden a principios de 2024, que busca abordar las vulnerabilidades en la seguridad de los datos que podrían dañar los intereses nacionales.
Mejorar la protección contra amenazas externas
Los requisitos propuestos se centran en entidades que manejan datos confidenciales a gran escala, particularmente en industrias como la inteligencia artificial, las comunicaciones, la atención médica, las finanzas y la contratación de defensa.
El principal temor de CISA es que los datos de estas organizaciones puedan caer en manos de “países de interés” o “personas cubiertas”, términos que el gobierno de Estados Unidos utiliza para referirse a adversarios extranjeros conocidos por participar en ciberespionaje y violaciones de datos.
Estos nuevos estándares de seguridad tienen como objetivo cerrar las lagunas que podrían exponer datos confidenciales a grupos patrocinados por el Estado y agencias de inteligencia extranjeras.
Suscríbase al boletín TechRadar Pro para recibir las principales noticias, opiniones, características y orientación que su empresa necesita para tener éxito.
Las empresas deberán mantener un inventario actualizado de sus activos digitales, incluidas direcciones IP y configuraciones de dispositivos, para estar preparadas ante posibles incidentes de seguridad. Las empresas también deberán aplicar múltiples factores Autenticación (MFA) en todos los sistemas críticos y requiere contraseñas de al menos 16 caracteres para evitar el acceso no autorizado.
La gestión de vulnerabilidades es otro enfoque clave, y las organizaciones deben abordar y remediar cualquier vulnerabilidad conocida o falla crítica explotada en un plazo de 14 días, incluso si la explotación no ha sido confirmada. Las vulnerabilidades de alto riesgo deben solucionarse en un plazo de 30 días.
La nueva propuesta también enfatiza la transparencia de la red y las empresas deben mantener topologías de red detalladas para mejorar su capacidad de identificar y responder a incidentes de seguridad.
Revocar inmediatamente el acceso de los empleados después de un despido o un cambio de función es esencial para evitar amenazas internas. Además, se evitará que dispositivos no autorizados, como dispositivos USB, se conecten a sistemas que manejan datos confidenciales, lo que reduce el riesgo de fuga de datos.
Además de las protecciones a nivel de sistema, la propuesta CISA introduce medidas sólidas a nivel de datos destinadas a minimizar la exposición de información personal y gubernamental. Se alentará a las organizaciones a recopilar solo los datos necesarios para sus operaciones y, cuando sea posible, anonimizarlos o anonimizarlos para evitar el acceso no autorizado. El cifrado desempeñará un papel fundamental a la hora de proteger los datos durante cualquier transacción que involucre una “entidad restringida”, garantizando que incluso si los datos son interceptados, no puedan descifrarse fácilmente.
La condición crucial es esta. Cifrado Las claves no deben almacenarse junto con los datos que protegen, especialmente en áreas identificadas como países de preocupación. Además, también se alentará a las organizaciones a adoptar tecnologías avanzadas que preserven la privacidad, como el cifrado simétrico o la privacidad diferencial, que permiten procesar datos sin revelar información subyacente.
CISA está buscando comentarios públicos sobre los requisitos propuestos para mejorar el marco antes de finalizarlo. Se invita a las partes interesadas, incluidos líderes de la industria y expertos en ciberseguridad, a enviar sus comentarios a través de regulaciones.gov ingresando CISA-2024-0029 en el campo de búsqueda y siguiendo las instrucciones para enviar comentarios.
La función Summon de Microsoft para Windows se ha visto envuelta en una controversia por cuestiones de privacidad
La herramienta utiliza inteligencia artificial para tomar capturas de pantalla constantemente y crear una línea de tiempo con capacidad de búsqueda de su actividad.
Se implementó un nuevo filtro de “información confidencial” para realizar pruebas, pero no parece estar funcionando bien
Así es chicos, es ese momento de la semana nuevamente: microsoft lo recuerdo una vez más Fracasó desde el principio, esta vez acusado de almacenar datos personales de los usuarios, como detalles de tarjetas de crédito y números de Seguro Social, incluso con el supuesto filtro de “información confidencial” activado.
Una característica muy controvertida anunciada originalmente para los dispositivos de PC Copilot+ en junio, Recall utiliza IA para tomar capturas de pantalla estáticas de todo lo que haces en tu PC y organizar esas capturas de pantalla en una línea de tiempo, lo que te permite “recordar” una vez. Volver a un punto anterior pidiendo a Copilot que busque nuevamente en el registro de su sistema.
Avram Piltch de TH realizó algunas pruebas en profundidad con Recall, investigando específicamente cómo supuestamente funciona el nuevo filtro de datos confidenciales. Resulta que no funciona nada bien: en múltiples aplicaciones y sitios web, solo se impidió que dos tiendas en línea permitieran a Recall tomar una captura de pantalla de los datos personales, incluso al ingresar información financiera en una página HTML dedicada mediante una entrada. cuadro que literalmente decía: “Ingrese su número de tarjeta de crédito a continuación”.
Obviamente, Piltch no publicó capturas de pantalla de los detalles de su tarjeta de crédito, pero sí señaló que probó su información real y Recall aun así la detectó. Sin embargo, la función de filtro (que supuestamente utiliza IA para identificar la información privada que se muestra en la pantalla) claramente todavía necesita algo de trabajo.
Microsoft ha puesto mucho esfuerzo en las funciones de seguridad de Recall, pero ha sido un camino difícil para la nueva función de IA. (Crédito de la imagen: Microsoft)
microsoft dice en su blog Planea “continuar mejorando esta funcionalidad” y que “puedes eliminar cualquier instantánea en Recall que no quieras y decirle a Recall que ignore esa aplicación o sitio web en esa instantánea de ahora en adelante”, pero tal como está ahora, los iniciados que usan la herramienta está poniendo efectivamente en riesgo sus datos. Las capturas de pantalla están cifradas y no se comparten con Microsoft ni con ningún tercero, pero mantener un registro completo del uso de su computadora de esta manera esencialmente crea la base de datos perfecta para que los delincuentes obtengan su información personal.
Regístrese para recibir noticias de última hora, reseñas, opiniones, las mejores ofertas tecnológicas y más.
Por supuesto, la función todavía está técnicamente bajo prueba, incluso si el público puede acceder a ella ahora, por lo que hay una buena posibilidad de que para cuando Recall llegue al lanzamiento completo (cuando sea que termine), estos problemas se habrán resuelto por completo. Pero con tantas preocupaciones en torno a esto, personalmente no creo que lo use; mi memoria es bastante buena, Microsoft.