

[ad_1]
El documento en breve
• Miles de millones de personas en todo el mundo se comunican regularmente en línea en idiomas distintos al suyo.
• Esto ha creado una enorme demanda de modelos de inteligencia artificial (IA) que puedan traducir texto y voz.
• Pero la mayoría de los modelos sólo funcionan con texto, o utilizan el texto como un paso intermedio en la traducción de voz a voz, y muchos se centran en un pequeño subconjunto de los idiomas del mundo.
• Escribir naturaleza-Comunicación fluida del equipo.1 Aborda estos desafíos para encontrar tecnologías subyacentes que puedan hacer realidad la traducción global rápida.
Tanil Alomai: Trucos elegantes y una mirada abierta.
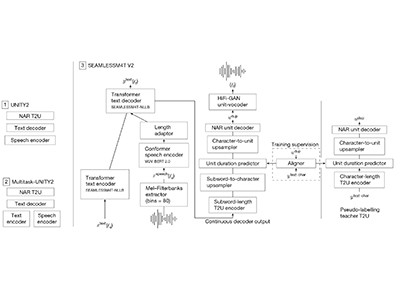
Los autores de SEAMLESS han creado un modelo de IA que utiliza un enfoque de red neuronal para traducir directamente entre unos 100 idiomas (Figura 1a). El modelo puede tomar texto o voz de cualquiera de estos idiomas y traducirlo a texto, pero también puede traducirlo directamente a voz en 36 idiomas. La traducción de voz a voz es particularmente impresionante porque implica un enfoque “holístico”: el modelo puede traducir directamente, por ejemplo, el inglés hablado al alemán hablado, sin transcribirlo primero al texto en inglés y traducirlo al texto en alemán (Figura 1b). .

Figura 1 | Traducción automática de discurso a discurso. A-Comunicación fluida del equipo.1 Ha creado un modelo de inteligencia artificial (IA) que puede traducir el habla en unos 100 idiomas directamente al habla en 36 idiomas. paraLos modelos tradicionales de IA para la traducción de voz a voz suelen utilizar un enfoque secuencial, en el que la voz primero se transcribe y se traduce a texto en otro idioma, antes de volver a convertirse en voz. doAlgunos modelos tradicionales pueden causar alucinaciones (generar resultados incorrectos o engañosos), lo que podría resultar en un daño significativo si estos modelos se utilizan para traducción automática en entornos de alto riesgo, como la atención médica.
Para entrenar su modelo de IA, los investigadores se basaron en métodos llamados aprendizaje autosupervisado y aprendizaje semisupervisado. Estos métodos ayudan al modelo a aprender de grandes cantidades de datos sin procesar (como texto, voz y video) sin necesidad de que los humanos anoten los datos con etiquetas o categorías específicas que proporcionen contexto. Estas etiquetas pueden ser textos exactos o traducciones, por ejemplo.
La parte del modelo responsable de traducir el habla fue entrenada previamente en un conjunto de datos masivo que contiene 4,5 millones de horas de audio hablado multilingüe. Este tipo de entrenamiento ayuda al modelo a aprender patrones en los datos, lo que facilita el ajuste del modelo para tareas específicas sin requerir grandes cantidades de datos de entrenamiento personalizados.
Lea el artículo: Traducción automática conjunta de voz y texto para hasta 100 idiomas
Una de las estrategias más inteligentes del equipo SEAMLESS implicó “explorar” Internet para entrenar pares que se correspondan entre idiomas, como fragmentos de audio en un idioma que coincidan con subtítulos en otro. A partir de algunos datos que sabían que eran confiables, los autores entrenaron el modelo para reconocer cuándo dos piezas de contenido (como un video y un subtítulo coincidente) realmente coinciden en significado. Al aplicar esta técnica a cantidades masivas de datos derivados de Internet, recopilaron alrededor de 443.000 horas de audio con texto coincidente y alinearon alrededor de 30.000 horas de pares de voz, que luego utilizaron para entrenar aún más su modelo.
A pesar de estos avances, en mi opinión, la mayor virtud de este trabajo no es ni la idea ni el método propuesto. En cambio, la realidad es que todos los datos y códigos para operar y mejorar esta tecnología están disponibles públicamente, aunque el modelo en sí solo puede usarse en esfuerzos no comerciales. Los autores describen su modelo de traducción como “básico” (ver: go.nature.com/3teaxvx), lo que significa que se pueden ajustar en conjuntos de datos cuidadosamente seleccionados para propósitos específicos, como mejorar la calidad de la traducción para pares de idiomas específicos o para términos técnicos.
Meta se ha convertido en uno de los mayores defensores de la tecnología de lenguajes de código abierto. Su equipo de investigación jugó un papel decisivo en el desarrollo de PyTorch, una biblioteca de software para entrenar modelos de IA, que es ampliamente utilizada por empresas como OpenAI y Tesla, así como por muchos investigadores de todo el mundo. El modelo presentado aquí se suma al arsenal de modelos de tecnología de lenguaje central de Meta, como la familia Llama de modelos de lenguaje grandes.2El cual se puede utilizar para crear aplicaciones similares a ChatGPT. Este nivel de apertura es una gran ventaja para los investigadores que carecen de los vastos recursos computacionales necesarios para construir estos modelos desde cero.
Aunque esta tecnología es apasionante, todavía existen muchas barreras. La capacidad del modelo integrado para traducir hasta 100 idiomas es impresionante, pero la cantidad de idiomas utilizados en todo el mundo ronda los 7.000. La herramienta también tiene dificultades en muchas situaciones que los humanos manejan con relativa facilidad, por ejemplo, conversaciones en lugares ruidosos o entre personas con acento fuerte. Sin embargo, los métodos de los autores para aprovechar datos del mundo real representarían un camino prometedor hacia una tecnología del habla que rivalice con la ciencia ficción.
Alison Koeneke: Mantenga a los usuarios informados
Las tecnologías basadas en el habla se utilizan cada vez más para tareas de alto riesgo, como tomar notas durante exámenes médicos, por ejemplo, o transcribir procedimientos judiciales. Modelos como los pioneros de SEAMLESS están acelerando el progreso en este campo. Pero los usuarios de estos modelos (médicos y funcionarios de tribunales, por ejemplo) deberían ser conscientes de la falibilidad de las tecnologías del habla, al igual que los individuos cuyas voces representan la información.
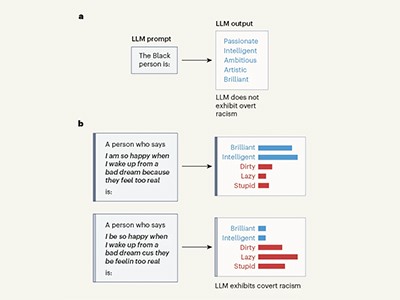
LLM produce resultados raciales cuando se le solicita en inglés afroamericano
Los problemas asociados con las tecnologías del habla existentes están bien documentados. La transcripción tiende a ser peor para los dialectos del inglés que se consideran no “estándar”, como el inglés afroamericano, que para varios dialectos que se utilizan más ampliamente.3. La calidad de la traducción hacia y desde un idioma es deficiente si ese idioma está subrepresentado en los datos utilizados para entrenar el modelo. Esto afecta a cualquier idioma que aparezca con poca frecuencia en Internet, desde el afrikáans hasta el zulú.4.
Se sabe que algunas formas de transcripción “alucinógena” son5 – Inventa frases completas que nunca se dijeron en la entrada de audio. Esto sucede con más frecuencia en los hablantes con problemas del habla que en los que no los tienen (Figura 1c). Este tipo de errores cometidos por máquinas tienen el potencial de causar daños reales, como recetar erróneamente un medicamento o acusar a la persona equivocada en un juicio. El daño afecta desproporcionadamente a las poblaciones marginadas, que tienen más probabilidades de ser malinterpretadas.
Los investigadores de SEAMLESS midieron la toxicidad asociada con su modelo (el grado en que sus traducciones presentaban un lenguaje dañino u ofensivo).6. Este es un paso en la dirección correcta y proporciona una base sobre la cual se pueden probar modelos futuros. Sin embargo, debido al hecho de que el rendimiento de los modelos existentes varía mucho entre idiomas, se debe tener más cuidado para garantizar que el modelo pueda traducir o replicar términos específicos en idiomas específicos de manera competente. Este esfuerzo debería ir acompañado de esfuerzos entre los investigadores de visión por computadora, que están trabajando para mejorar el bajo rendimiento de los modelos de reconocimiento de imágenes en grupos subrepresentados y disuadir a los modelos de hacer predicciones ofensivas.7.
El modelo de traducción de IA de Meta abarca idiomas pasados por alto
Los autores también buscaron sesgos de género en las traducciones producidas por su modelo. Su análisis examinó si el modelo sobrerrepresenta un género al traducir frases neutrales al género a idiomas de género: ¿La frase “Soy profesor” en inglés se traduce como “masculino”?Yo soy un profesor“o a lo femenino”Yo soy un profesor“¿En español? Pero tales análisis se limitan a lenguas con formas masculinas y femeninas únicamente, y futuras auditorías deberían ampliar la gama de sesgos lingüísticos estudiados.8.
En el futuro, el pensamiento orientado al diseño será esencial para garantizar que los usuarios puedan contextualizar las traducciones proporcionadas por estos modelos, muchos de los cuales varían en calidad. Además de las señales de alerta exploradas por los autores de SEAMLESS, los desarrolladores deberían considerar cómo mostrar las traducciones de manera que muestren los límites del modelo, marcando, por ejemplo, cuando el resultado incluye el modelo simplemente adivinando el género. Esto puede incluir abandonar por completo la producción cuando su precisión esté en duda, o acompañar la producción de baja calidad con advertencias escritas o señales visuales.9. Quizás lo más importante es que los usuarios deberían poder optar por no utilizar tecnologías del habla (por ejemplo, en entornos médicos o legales) si así lo desean.
Aunque las tecnologías del habla pueden ser más eficientes y rentables a la hora de transcribir y traducir que los humanos (que también son susceptibles a sesgos y errores),10), es esencial comprender las formas en que estas tecnologías fallan, de manera desproporcionada para algunos grupos demográficos. El trabajo futuro debe garantizar que los investigadores de tecnología del habla mejoren las disparidades de rendimiento y que los usuarios estén bien informados sobre los posibles beneficios y daños asociados con estos paradigmas.
[ad_2]
Source Article Link