

[ad_1]
Internet es un vasto océano de conocimiento humano, pero no es ilimitado. Y los investigadores de IA casi lo han aguantado.
La última década de espectacular mejora en la IA ha sido impulsada en gran medida por: Haga las redes neuronales más grandes y entrénelas con más datos. Esta expansión ha demostrado ser sorprendentemente eficaz a la hora de hacer que los grandes modelos de lenguaje (LLM), como los que impulsan el chatbot ChatGPT, sean más capaces de replicar el lenguaje conversacional y desarrollar propiedades emergentes, como la inferencia. Pero algunos especialistas dicen que ahora nos estamos acercando a los límites de la expansión. Esto se debe en parte a Requisitos de energía inflados para la informática. Pero también se debe a que los desarrolladores de LLM se están quedando sin conjuntos de datos tradicionales utilizados para entrenar sus modelos.
Estudio sobresaliente1 Este año fue noticia al ponerle un número al problema: investigadores de Epoch AI, un instituto de investigación de virtualización, predicen que alrededor de 2028, el tamaño típico del conjunto de datos utilizado para entrenar un modelo de IA alcanzará el mismo tamaño total estimado. Inventario de textos públicos en línea. En otras palabras, es más probable que la IA lo haga. Nos quedamos sin datos de entrenamiento en unos cuatro años (Ver “Sin datos”). Al mismo tiempo, los propietarios de datos –como los editores de periódicos– han comenzado a tomar medidas enérgicas sobre cómo se utiliza su contenido, restringiendo aún más el acceso a los datos. Esto crea una crisis en el tamaño de los “datos comunes”, dice Shane Longbury, investigador de IA en el Instituto de Tecnología de Massachusetts en Cambridge, que dirige la Data Source Initiative, una organización de base que realiza auditorías de conjuntos de datos de IA.
El inminente cuello de botella en los datos de entrenamiento puede estar comenzando a disminuir. “Dudo mucho que esto esté sucediendo realmente”, dice Longbury.
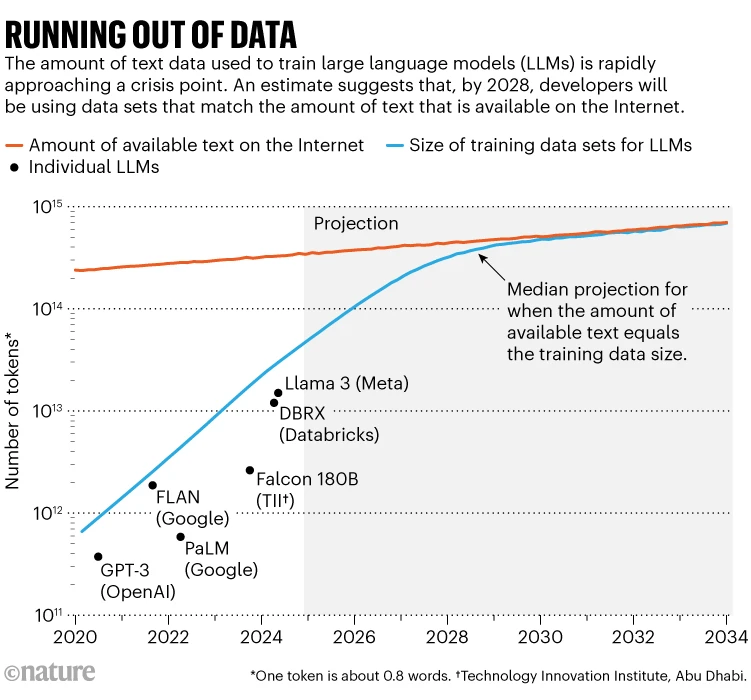
Fuente: Referencia. 1
Aunque los especialistas dicen que existe la posibilidad de que estas limitaciones ralenticen la rápida mejora de los sistemas de IA, los desarrolladores están encontrando soluciones. “No creo que nadie esté entrando en pánico por las grandes empresas de IA”, dice Pablo Villalobos, investigador de Epoch AI con sede en Madrid y autor principal del estudio que predice un colapso de los datos en 2028. “O al menos no me envían correos electrónicos si lo hacen”.
Por ejemplo, destacadas empresas de inteligencia artificial como OpenAI y Anthropic, ambas con sede en San Francisco, California, han reconocido públicamente este problema y han sugerido que tienen planes para superarlo, incluida la generación de nuevos datos y la búsqueda de fuentes de datos no tradicionales. Un portavoz de OpenAI dijo naturaleza: “Utilizamos muchas fuentes, incluidos datos disponibles públicamente, asociaciones para datos no públicos, generación de datos sintéticos y datos de entrenadores de IA”.
Sin embargo, la crisis de datos puede revolucionar los tipos de modelos de IA generativa que la gente construye, quizás cambiando el panorama de grandes MBA multipropósito a modelos más pequeños y más especializados.
Billones de palabras
El desarrollo de LLM durante la última década ha demostrado su insaciable apetito por los datos. Aunque algunos desarrolladores no publican especificaciones para sus últimos modelos, Villalobos estima que la cantidad de “tokens” o partes de palabras utilizadas para capacitar a los LLM se ha multiplicado por 100 desde 2020, de cientos de miles de millones a decenas de billones.

En IA, ¿más grande siempre es mejor?
Esto podría ser una porción significativa de lo que hay en Internet, aunque el total general es demasiado grande para cuantificarlo: Villalobos estima que el stock total de datos textuales de Internet hoy es de aproximadamente 3.100 billones de tokens. Varios servicios utilizan rastreadores web para extraer este contenido, luego eliminan duplicados y filtran contenido no deseado (como pornografía) para producir conjuntos de datos más nítidos: un servicio popular llamado RedPajama contiene decenas de billones de palabras. Algunas empresas o académicos rastrean y limpian ellos mismos para crear conjuntos de datos personalizados para la formación de MBA. Un pequeño porcentaje de Internet es de alta calidad, como textos socialmente aceptables y editados por humanos que se pueden encontrar en libros o en la prensa.
La tasa de aumento del contenido utilizable de Internet es sorprendentemente lenta: la investigación de Villalobos estima que está creciendo a menos del 10% por año, mientras que el tamaño de los conjuntos de datos de entrenamiento de IA se duplica anualmente. La proyección de estas tendencias muestra asíntotas alrededor de 2028.
Al mismo tiempo, los proveedores de contenido incluyen cada vez más códigos de programación o mejoran sus condiciones de uso para evitar que los rastreadores web o las empresas de inteligencia artificial extraigan sus datos para capacitación. Longpre y sus colegas publicaron una preimpresión en julio de este año que muestra un fuerte aumento en la cantidad de proveedores de datos que bloquean el acceso de ciertos rastreadores a sus sitios web.2. En el contenido web de alta calidad y más utilizado en los tres principales conjuntos de datos limpiados, la cantidad de tokens bloqueados por los rastreadores aumentó de menos del 3% en 2023 al 20-33% en 2024.
Actualmente se están presentando varias demandas para tratar de obtener daños y perjuicios para los proveedores de datos utilizados en la formación de IA. En diciembre de 2023, New York Times Presentó una demanda contra OpenAI y su socio Microsoft por infracción de derechos de autor; En abril de este año, ocho periódicos propiedad de Alden Global Capital en la ciudad de Nueva York presentaron una demanda similar. El contraargumento es que a la IA se le debería permitir leer y aprender del contenido en línea de la misma manera que lo haría una persona, y que esto constituye un uso justo del material. OpenAI ha dicho públicamente el cree New York Times La demanda es “infundada”.
Si los tribunales confirman la idea de que los proveedores de contenidos merecen una compensación financiera, será más difícil para los desarrolladores e investigadores de IA obtener lo que necesitan, incluidos los académicos, que no cuentan con recursos financieros significativos. “Los académicos serán los más afectados por estos acuerdos”, dice Longbury. “Hay muchos beneficios sociales y muy democráticos que se obtienen al tener una red abierta”, añade.
encontrar datos
La escasez de datos plantea un problema potencialmente importante para la estrategia tradicional de escalar la IA. Aunque es posible aumentar la potencia de cálculo de un modelo o la cantidad de parámetros sin ampliar los datos de entrenamiento, hacerlo da como resultado una IA lenta y costosa, dice Longbury, lo cual generalmente no es deseable.
Si el objetivo es encontrar más datos, una opción podría ser recopilar datos no públicos, como mensajes de WhatsApp o transcripciones de vídeos de YouTube. Aunque aún no se ha probado la legalidad de extraer contenido de terceros de esta manera, las empresas tienen la capacidad de acceder a sus propios datos y muchas empresas de redes sociales dicen que utilizan su propio material para entrenar sus propios modelos de IA. Por ejemplo, Meta, con sede en Menlo Park, California, dice que el audio y las imágenes recopiladas por sus auriculares de realidad virtual Meta Quest se utilizan para entrenar su IA. Sin embargo, las políticas varían. Los términos de servicio de la plataforma de videoconferencia Zoom establecen que la compañía no utilizará el contenido del cliente para entrenar sistemas de inteligencia artificial, mientras que OtterAI, un servicio de transcripción, dice que utiliza audio y texto cifrados y anónimos para la capacitación.

Cómo los chips informáticos de última generación están acelerando la revolución de la inteligencia artificial
Sin embargo, por el momento, este contenido propietario probablemente contenga otros mil billones de caracteres de texto en total, estima Villalobos. Dado que gran parte de este contenido es de baja calidad o está duplicado, dice que eso es suficiente para retrasar la limitación de datos en un año y medio, incluso suponiendo que una sola IA pueda acceder a todo sin causar infracción de derechos de autor o problemas de privacidad. . “Incluso multiplicar por diez el inventario de datos sólo es suficiente para tres años de expansión”, afirma.
Otra opción podría ser centrarse en conjuntos de datos especializados, como datos astronómicos o genómicos, que están creciendo rápidamente. Fei-Fei Li, un destacado investigador de IA de la Universidad de Stanford en California, ha respaldado públicamente esta estrategia. Las preocupaciones sobre quedarse sin datos adoptan una visión demasiado estrecha de lo que constituyen datos, dada la información no explotada disponible en áreas como la atención sanitaria, el medio ambiente y la educación, dijo en una Cumbre de Tecnología de Bloomberg en mayo pasado.
Pero no está claro, dice Villalobos, qué tan disponibles o útiles son estos conjuntos de datos para capacitar a los titulares de un LLM. “Parece haber cierto grado de transferencia de aprendizaje entre muchos tipos de datos”, afirma Villalobos. “Sin embargo, no soy muy optimista acerca de este enfoque.”
Las posibilidades son más amplias si la IA generativa se entrena con otros tipos de datos, no solo con texto. Algunos modelos ya son capaces de entrenar hasta cierto punto con vídeos o imágenes sin etiquetar. Ampliar y mejorar estas capacidades puede abrir la puerta a datos más ricos.
Yann LeCun, científico senior de IA en Meta e informático de la Universidad de Nueva York, considerado uno de los fundadores de la IA moderna, destacó estas posibilidades en una presentación de febrero en la AI Meeting en Vancouver, Canadá. 1013 Los símbolos utilizados para formar a un MBA moderno parecen muchos: a una persona le llevaría 170.000 años leer tanto, estima LeCun. Pero dice que un niño de 4 años absorbió 50 veces más datos simplemente mirando objetos durante sus horas de vigilia. LeCun presentó los datos en la reunión anual de la Asociación para el Avance de la Inteligencia Artificial.
[ad_2]
Source Article Link