
If you are creating programs and applications linked to OpenAI’s services such as ChatGPT it is important that you understand the rate limits which have been set for your particular AI model and how you can increase them if needed as well as the costs involved. Understanding the intricacies of an API’s rate limits is crucial for developers, businesses, and organizations that rely on that service for their operations. One such API is the ChatGPT API, which has its own set of rate limits that users must adhere to. This article will delve into the specifics of the ChatGPT API rate limits and explain why they are in place.
What are API rate limits?
Rate limits, in essence, are restrictions that an API imposes on the number of times a user or client can access the server within a specific period. They are common practice in the world of APIs and are implemented for several reasons. Firstly, rate limits help protect against abuse or misuse of the API. They act as a safeguard against malicious actors who might flood the API with requests in an attempt to overload it or disrupt its service. By setting rate limits, OpenAI can prevent such activities.
Secondly, rate limits ensure that everyone has fair access to the API. If one user or organization makes an excessive number of requests, it can slow down the API for everyone else. By controlling the number of requests a single user can make, OpenAI ensures that the maximum number of people can use the API without experiencing slowdowns.
Understanding OpenAI ChatGPT API rate limits
Rate limits help OpenAI manage the aggregate load on its infrastructure. A sudden surge in API requests could stress the servers and cause performance issues. By setting rate limits, OpenAI can maintain a smooth and consistent experience for all users.
Other articles we have written that you may find of interest on the subject of OpenAI and APIs :
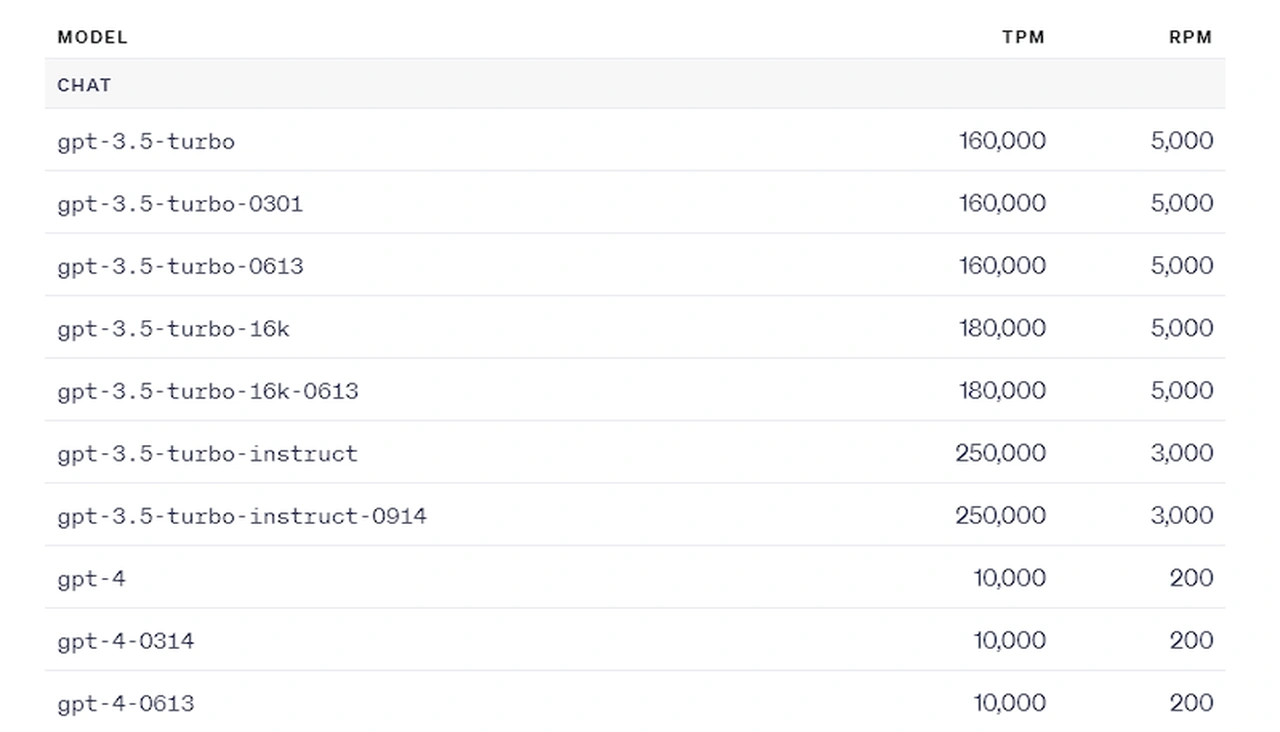
The ChatGPT API rate limits are enforced at the organization level, not the user level, and they depend on the specific endpoint used and the type of account. They are measured in three ways: RPM (requests per minute), RPD (requests per day), and TPM (tokens per minute). A user can hit the rate limit by any of these three options depending on what occurs first.
For instance, if a user sends 20 requests with only 100 tokens to the Completions endpoint and their RPM limit is 20, they will hit the limit, even if they did not send 150k tokens within those 20 requests. OpenAI automatically adjusts the rate limit and spending limit (quota) based on several factors. As a user’s usage of the OpenAI API increases and they successfully pay the bill, their usage tier is automatically increased.
For example, the first three usage tiers are as follows:
- Free Tier: The user must be in an allowed geography. They have a maximum credit of $100 and request limits of 3 RPM and 200 RPD. The token limit is 20K TPM for GPT-3.5 and 4K TPM for GPT-4.
- Tier 1: The user must have paid $5. They have a maximum credit of $100 and request limits of 500 RPM and 10K RPD. The token limit is 40K TPM for GPT-3.5 and 10K TPM for GPT-4.
- Tier 2: The user must have paid $50 and it must be 7+ days since their first successful payment. They have a maximum credit of $250 and a request limit of 5000 RPM. The token limit is 80K TPM for GPT-3.5 and 20K TPM for GPT-4.
In practice, if a user’s rate limit is 60 requests per minute and 150k tokens per minute, they’ll be limited either by reaching the requests/min cap or running out of tokens—whichever happens first. For instance, if their max requests/min is 60, they should be able to send 1 request per second. If they send 1 request every 800ms, once they hit the rate limit, they’d only need to make their program sleep 200ms in order to send one more request. Otherwise, subsequent requests would fail.
Understanding and adhering to the ChatGPT API rate limits is crucial for the smooth operation of any application or service that relies on it. The limits are in place to prevent misuse, ensure fair access, and manage the load on the infrastructure, thus ensuring a consistent and efficient experience for all users.
OpenAI enforces rate limits on the requests you can make to the API. These are applied over tokens-per-minute, requests-per-minute (in some cases requests-per-day), or in the case of image models, images-per-minute.
Increasing rate limits
OpenAI explains a little more about its API rate limits and when you should consider applying for an increase if needed:
“Our default rate limits help us maximize stability and prevent abuse of our API. We increase limits to enable high-traffic applications, so the best time to apply for a rate limit increase is when you feel that you have the necessary traffic data to support a strong case for increasing the rate limit. Large rate limit increase requests without supporting data are not likely to be approved. If you’re gearing up for a product launch, please obtain the relevant data through a phased release over 10 days.”
For more information on the OpenAI rate limits for its services such as ChatGPT jump over to the official guide documents website for more information and figures.
How to manage API rate limits :
- Understanding the Limits – Firstly, you need to understand the specifics of the rate limits imposed by the ChatGPT API. Usually, there are different types of limits such as per-minute, per-hour, and per-day limits, as well as concurrency limits.
- Caching Results – For frequently repeated queries, consider caching the results locally. This will reduce the number of API calls you need to make and can improve the responsiveness of your application.
- Rate-Limiting Libraries – There are rate-limiting libraries and modules available in various programming languages that can help you manage API rate limits. They can automatically throttle your requests to ensure you stay within the limit.
- Queuing Mechanism – Implementing a queuing mechanism can help you handle bursts of traffic efficiently. This ensures that excess requests are put in a queue and processed when the rate limit allows for it.
- Monitoring and Alerts – Keep an eye on your API usage statistics, and set up alerts for when you are nearing the limit. This can help you take timely action, either by upgrading your plan or optimizing your usage.
- Graceful Degradation – Design your system to degrade gracefully in case you hit the API rate limit. This could mean showing a user-friendly error message or falling back to a less optimal operation mode.
- Load Balancing – If you have multiple API keys or accounts, you can distribute the load among them to maximize your allowed requests.
- Business Considerations – Sometimes, it might be more cost-effective to upgrade to a higher tier of the API that allows for more requests, rather than spending engineering resources to micro-optimize API usage.
Filed Under: Guides, Top News
Latest timeswonderful Deals
Disclosure: Some of our articles include affiliate links. If you buy something through one of these links, timeswonderful may earn an affiliate commission. Learn about our Disclosure Policy.